玩转Prometheus(4)–发现异常节点
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 前言
一个服务常常运行几十或者上百个实例上。通过使用docker容器或者有意的为之,我们会控制实例运行的环境完全一致。因为docker容器所处或者虚拟机是与其他容器或者虚拟机共存的(同一个物理机)。又或者因为物理机的硬件设备的潜在故障,某些实例会表现出异常的行为。(也有可能是程序本身的原因) 如何找到异常节点就变得十分重要。
2. 分析&展示报警
这种节点往往会表现出以下的特点
- 请求超时
- 请求错误多
2.1 监控图表
在监控图表上,以非200请求举例,我们可以使用topk列出失败请求最多的实例
topk(3, sum(rate(http_requests_total{project="fake-service", run_mode="product", status!~"200|201|204"}[5m])) by (instance))
列出HTTP状态码非200的最多的3个实例
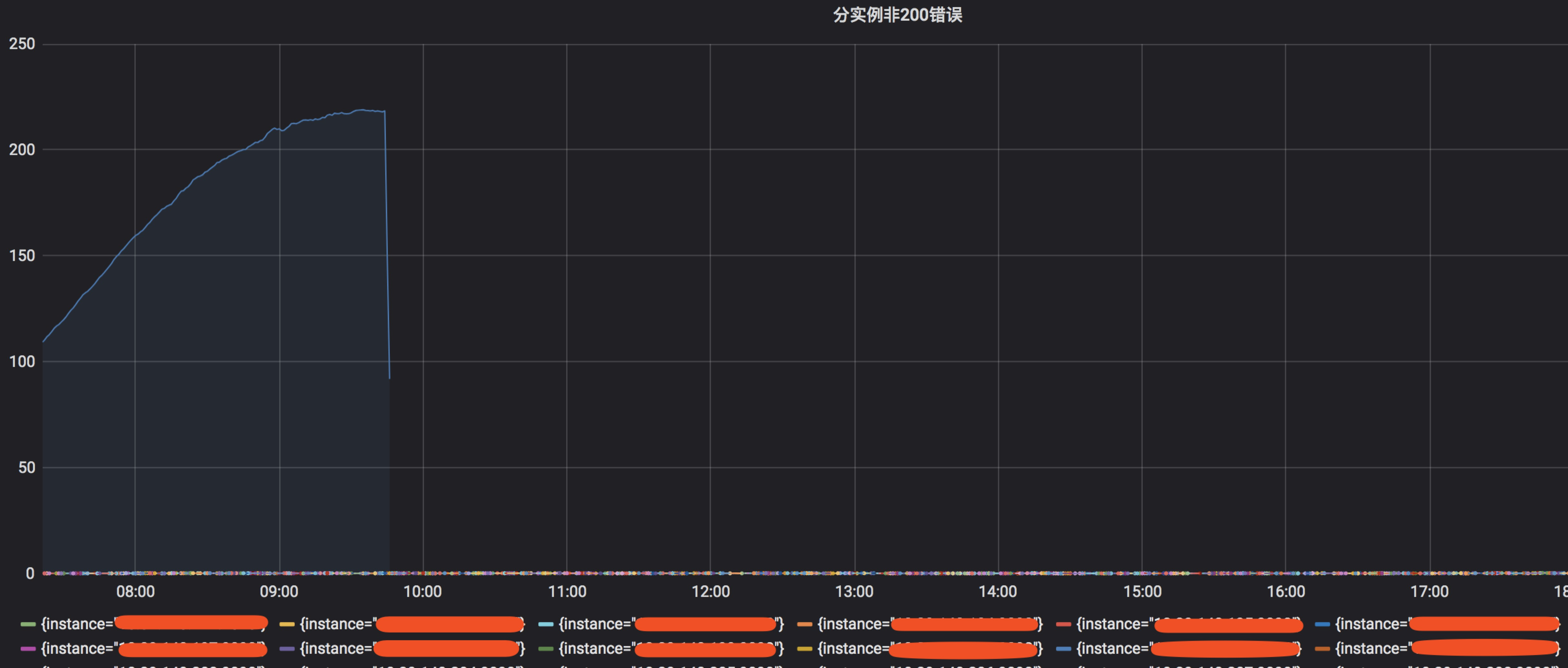
图1
从图1我们看出蓝色曲线的实例,非200的HTTP请求数量显著的高于其他实例
2.2 配置报警
参考资料2推荐这样去发现异常实例,如果
某个实例指标的值 > 所有实例指标的平均值 + 2 * 所有实例指标的标准差
那么可能有异常实例存在
DSL
floor(max(sum(rate(http_requests_total{project="sdk-api", run_mode="product", status!~"200|201|204"}[5m])) by (instance))) > avg(sum(rate(http_requests_total{project="sdk-api", run_mode="product", status!~"200|201|204"}[5m])) by (instance)) + 2 * stddev(sum(rate(http_requests_total{project="sdk-api", run_mode="product", status!~"200|201|204"}[5m])) by (instance))
后记
前几天线上就发生了一起这样的故障。找到异常节点,并重启后,故障恢复,报警解出。
参考资料
