聊聊Raft的一个实现(1)–goraft
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 前言
最近花了不少时间来学习raft相关的知识,写这篇文章的目的
- 1)为了对raft中让我困惑的问题进行总结
- 2) 为了对其它人的阅读便利,提供必要的帮助
网上raft的实现不少,但能够独立运行的样本工程实在不多。我选择的是
goraft/raftd
raft的paper是为数不多的连实现都写的比较清楚的文档,因此在阅读本文前,请确保你已经大致了解过raft的协议
2. 概述
goraft/raftd 依赖 goraft/raft, goraft/raft是分布式一致性算法raft的实现,而goraft/raftd 已经可以称之最简单的分布式key-value数据库(服务)了
聊到一个服务,我们最常用的手法,
1. 看它的接口。
2. 看它的数据如何存储,包括内部的数据结构,数据如何落地
2.1 接口
接口大致可以分为2组
2.1.1 HTTP之上RPC协议
这其实goraft的作者对raft协议所要求的几个RPC的实现,包括
- AppendEntries RPC
- RequestVote RPC
- Snapshot RPC (非raft协议要求的)
- SnapshotRecovery RPC (非raft协议要求的)
2.1.2 普通的HTTP API
- POST /db/{key} 写入key-value
curl -XPOST localhost:4001/db/foo -d 'bar'
- GET /db/{key} 读取key对应的value
curl localhost:4001/db/foo
- POST /join 把某个节点加入集群
curl http://localhost:4001/join -d '{"name":"5f2ac6d","connectionString":"http://localhost:4001"}'
这里有3个有趣的事情
1)这个节点可以是虚假的节点
2)由于JoinCommand 本身也是一条LogEntry, 所以当这条消息被发给Leader时,Cluster中的所有成员都会知道有一个新节点的加入(加入 raft.Server.peers)
3) 1个节点掉线后,它不会从raft.Server.peers移除
为了便于观察raft.Server的内部状态
我又扩充了3个接口 传送门vearne/raftd
- GET /members 显示此节点看到peers
curl http://localhost:4001/members
raft.Server.peers 存储的是除去它本身以外,它所知道的Cluster
* GET /leader 显示此节点所知的当前Leader
curl http://localhost:4001/leader
- GET /state 显示此节点state信息
curl http://localhost:4001/state
返回样例
"Name: 2832bfa, State: candidate, Term: 472, CommitedIndex: 25 "
2.2 数据的存储
2.2.1 持久化存储
假定raftd的data-path 在node.1中
-rw------- 1 11 28 15:59 conf # peers和commitIndex
-rw------- 1 11 28 13:23 log # log
-rw-r--r-- 1 11 28 10:44 name # 此节点的名称
drwx------ 2 11 28 10:44 snapshot
conf的中的内容形如
{"commitIndex":25,"peers":[{"name":"3320b68","connectionString":"http://localhost:4002"},{"name":"7bd5bdc","connectionString":"http://localhost:4003"},{"name":"xxxxx","connectionString":"http://localhost:4004"}]
log文件中的内容形如
4f
raft:join">{"name":"2832bfa","connectionString":"http://localhost:4001"}
e
raft:nop 4f
raft:join">{"name":"3320b68","connectionString":"http://localhost:4002"}
4f
raft:join">{"name":"7bd5bdc","connectionString":"http://localhost:4003"}
e
raft:nop 29
write"{"key":"foo","value":"bar"}
29
write"{"key":"aaa","value":"bbb"}
29
write"{"key":"bbb","value":"ccc"}
29
write"{"key":"ddd","value":"eee"}
e
raft:nop e
raft:nop 29
write"{"key":"foo","value":"bar"}
29
write"{"key":"foo","value":"bar"}
raft中的log文件,相当于Redis中的Aof, 或者MySQL中的bin log,cluster中的每1条Command
都会在log中被记录下来。它本身是一个二进制文件,但是使用cat命令仍然能够看个大概
- raft:join 对应的是
JoinCommand - raft:nop 对应的是
NOPCommand - write 对应的是
WriteCommand
注:在goraft中, 读操作可以在非Leader上执行
2.2.2 状态机
raftd中的状态机简单讲
// The key-value database.
type DB struct {
data map[string]string
mutex sync.RWMutex
}
如果考虑上JoinCommand, 那么Peers也算状态机的一部分
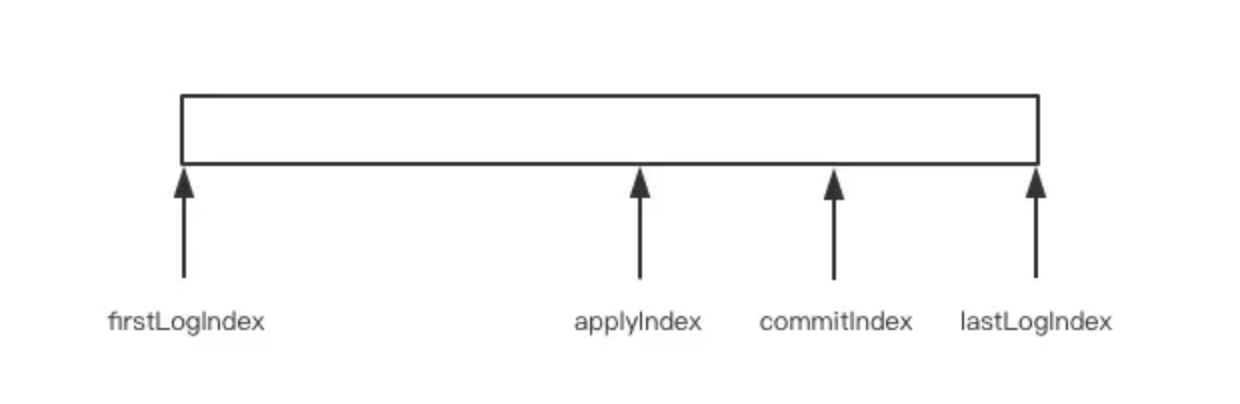
firstLogIndex/lastLogIndex标识当前日志序列的起始位置,如果日志不做压缩处理,也就是没有快照模块的话,那么firstLogIndex就是零值。在goraft中,firstLogIndex就是startIndexcommitIndex表示当前已经提交的日志,也就是成功同步到majority的日志位置的最大值applyIndex是已经apply到状态机的日志索引,它的值必须小于等于commitIndex,因为只有已经提交的日志才可以apply到状态机
由此我们可以知道状态机是所有Command(从index 0到applyIndex) 逐条执行,所造成的结果。类似于我们拿着画笔画画,Command是一笔一笔的涂抹动作,状态机是最后的画作。 接口GET /db/{key} 读取key对应的value,就是针对状态机中状态的查询。
绝大多数情况下applyIndex和commitIndex是完全相等的,因为对状态机的写入操作非常的快。
commit是非常有趣的操作,在下一篇文章中,我会更详细的阐述。
2.2.3 其它volatile state
有兴趣的朋友可以对比下raft paper中的State
主要都在以下2个结构中
raft/server.go
type server struct {
*eventDispatcher
name string
path string
state string
transporter Transporter
context interface{}
currentTerm uint64
votedFor string
log *Log
leader string
peers map[string]*Peer
mutex sync.RWMutex
syncedPeer map[string]bool
stopped chan bool
c chan *ev
electionTimeout time.Duration
heartbeatInterval time.Duration
...
}
raft/log.go
type Log struct {
ApplyFunc func(*LogEntry, Command) (interface{}, error)
file *os.File
path string
entries []*LogEntry
commitIndex uint64
mutex sync.RWMutex
startIndex uint64 // the index before the first entry in the Log entries
startTerm uint64
initialized bool
}
2.3 核心代码
核心代码主要在
raft/server.go
func (s *server) loop() {
defer s.debugln("server.loop.end")
state := s.State()
for state != Stopped {
s.debugln("server.loop.run ", state)
switch state {
case Follower:
s.followerLoop()
case Candidate:
s.candidateLoop()
case Leader:
s.leaderLoop()
case Snapshotting:
s.snapshotLoop()
}
state = s.State()
}
}
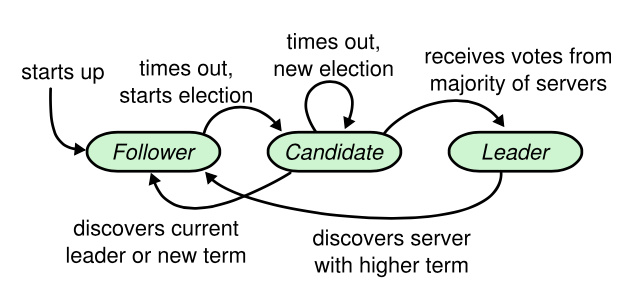
节点的状态在沿着箭头方向,按一定条件发生着变化。
在goraft的具体实现中,节点还有2个额外状态Initialized和Stopped,前者表示节点正在启动初始化中,后者表示节点已经停止。
节点的绝大多数情况下,都是被动的处理各种event
- 1 follower loop
- 1.1 JoinCommand
- 1.2 AppendEntriesRequest
- 1.3 RequestVoteRequest
- 1.4 SnapshotRequest
- 2 candidate loop
- 2.1 Send VoteRequest (主动)
- 2.2 AppendEntriesRequest
- 2.3 RequestVote
- 3 leader loop
- 3.1 Heartbeat (主动) 注:包含发送 AppendEntriesRequest
- 3.2 Command 可能来自HTTP API的 JoinCommand/WriteCommand
- 3.3 AppendEntriesRequest
- 3.4 AppendEntriesResponse
- 3.5 RequestVoteRequest
snapshotLoop 不做讨论,上面除表明主动的,其余都是被动的处理event
参考资料
- In Search of an Understandable Consensus Algorithm
- In Search of an Understandable Consensus Algorithm 中文翻译
- Raft协议精解
