玩转KCP(3)-流量控制
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 前言
KCP协议的很多东西都是脱胎于TCP协议,所以他们在思想和实现上是完全相通的。xtaci/kcp-go 包含FEC也不过4000多行代码,skywind3000/kcp 主要是C/C++的代码,也就2000多行,萌叔建议大家都去阅读下源码。
慢启动、拥塞避免、拥塞发生、快速重传,这些概念都非常唬人,但看完代码你会发现不过尔尔。
在开始正式的文章之前,萌叔打算问几个问题?
- 流控是为了保护谁?
- 在实现中如何体现?
2. 流控是为了保护谁?
TCP是全双工,这里简化一下,我们只看半双工的情况
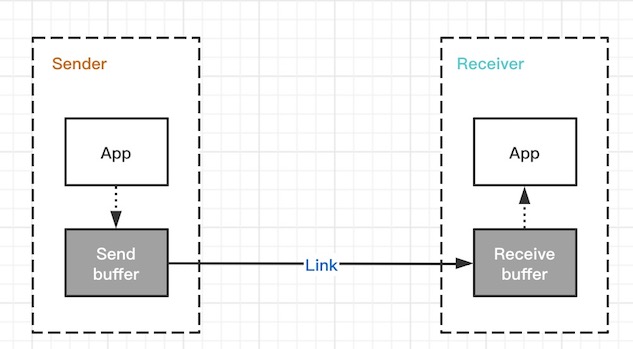
Sender发送数据给Receiver
1) Sender中的应用程序把数据写入到本机的发送缓冲区
2) 数据从发送缓冲区写入到链路中,链路可能是由实际的光缆、电缆、多个路由器节点组成。
3)数据从链路转交到Receiver的接收缓冲区
4)数据从接收缓冲区交给Receiver的应用程序
- 发送缓冲区大小是有限的,它必须被保护起来
Sender和Receiver之间的链路的收发能力也是有限的,且是与网络中的其它节点共享的,因此Link也必须受到保护- 接收缓冲区大小也是受限的,它也应该受到保护
3. 在实现中如何体现?
在实际实现中每一个需要保护的点,都有与之对应的参数,先上结论
3.1 使用发送端的发送窗口(snd_wnd)保护本机的发送缓冲区
3.2 使用拥塞窗口(cwnd)来保护发送端与接收端之间的链路
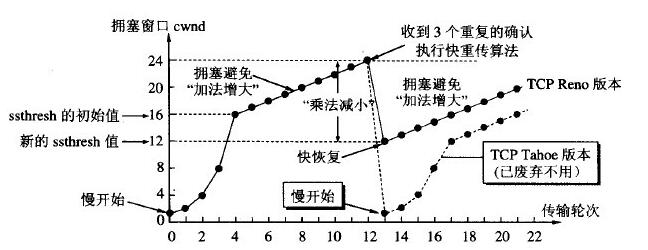
cwnd是动态变化的值, 算法与TCP协议基本相同
3.3 使用接收端的接收窗口(rmt_wnd, 表示接收窗口的空闲大小)保护接收端的接收缓冲区
rmt_wnd对应KCP协议的wnd, 由接收端汇报
回顾一下KCP协议
0 4 5 6 8 (BYTE)
+---------------+---+---+-------+
| conv |cmd|frg| wnd |
+---------------+---+---+-------+ 8
| ts | sn |
+---------------+---------------+ 16
| una | len |
+---------------+---------------+ 24
| |
| DATA (optional) |
| |
+-------------------------------+
4. 分析一次完整的写入动作
4.1 发送窗口和接收窗口对写入的影响
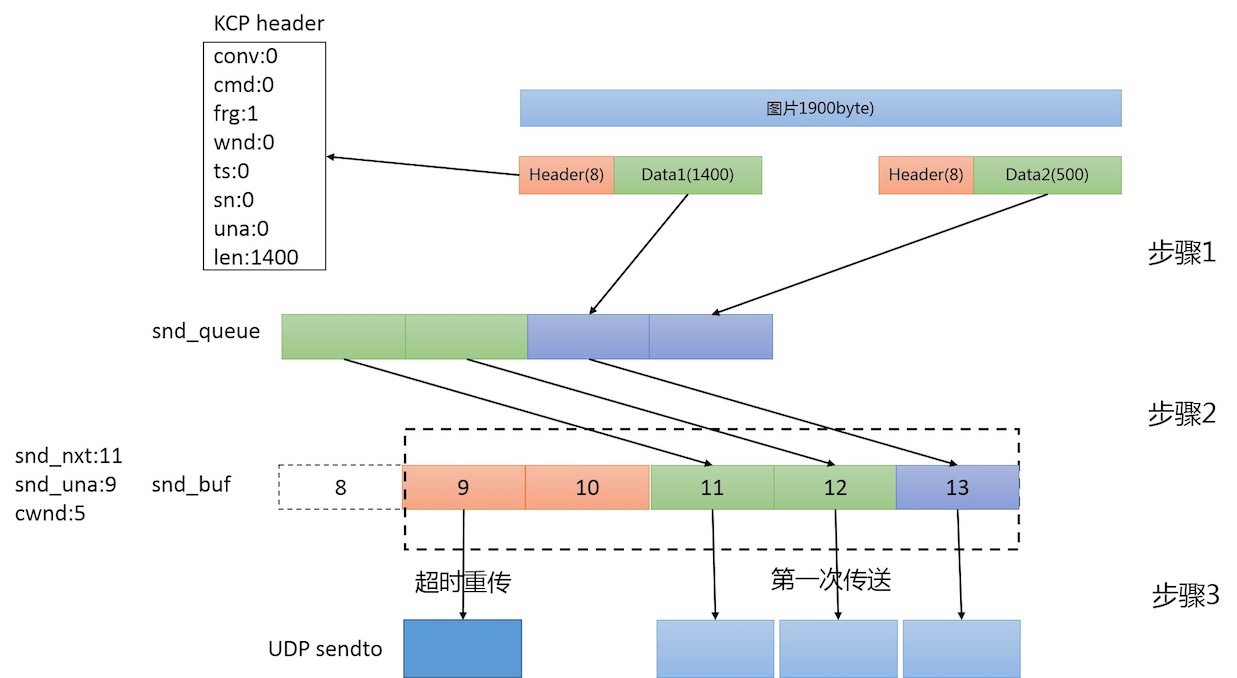
在KCP中,数据被拆分成Segment后
step1:先写入snd_queue
step2:从snd_queue移动到snd_buf
step3:snd_buf中的Segment,通过UDP套接字发出(flushBuffer())
完整代码见sess.go
func (s *UDPSession) WriteBuffers
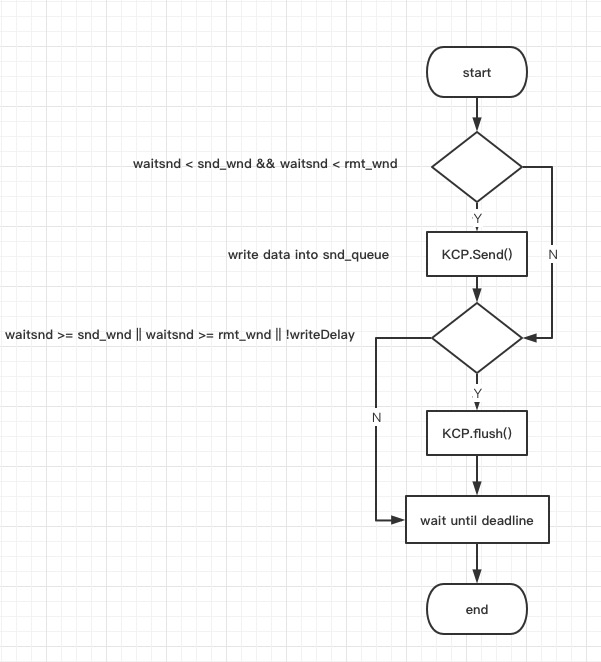
补充说明 waitsnd的计算方法如下
// WaitSnd gets how many packet is waiting to be sent
func (kcp *KCP) WaitSnd() int {
return len(kcp.snd_buf) + len(kcp.snd_queue)
}
从上面的流程图可以看出,如果在写入函数中,KCP首先尝试写发送缓冲区,如果发送缓冲区已经满了或者设置了
sess.SetWriteDelay(true)
KCP还会尝试立马执行flush操作,以释放发送缓冲区的空间。如果还是无法写入,那么只能等待写超时。
注意 除了WriteBuffers函数会执行flush操作,KCP内部还有一个定时器,周期性的调用flush函数。
// sess updater to trigger protocol
func (s *UDPSession) updater() {
timer := time.NewTimer(0)
for {
select {
case <-timer.C:
s.mu.Lock()
interval := time.Duration(s.kcp.flush(false)) * time.Millisecond
waitsnd := s.kcp.WaitSnd()
if waitsnd < int(s.kcp.snd_wnd) && waitsnd < int(s.kcp.rmt_wnd) {
s.notifyWriteEvent()
}
s.uncork()
s.mu.Unlock()
timer.Reset(interval)
case <-s.die:
timer.Stop()
return
}
}
}
4.2 拥塞窗口对写入的影响
注意:在KCP协议中,拥塞控制可以被关闭
让我们把注意力集中到snd_buff上
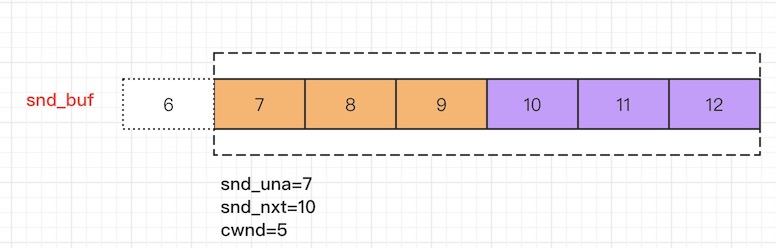
某一时刻,snd_buf的情况如上图
snd_una表示未被ack的Segment的最小编号snd_nxt表示下一个待发送的Segment的编号
可见 snd_una和 snd_nxt之间的橘色区域就是所有没有被确认的Segment(粗略的认为)。这部分Segment目前正在发送端和接收端之间的链路上"飞",为了避免链路拥塞,KCP希望限制这部分的区域应该小于cwnd
在实际的KCP实现中,
// 拥塞窗口已满
if(kcp.snd_nxt - kcp.snd_una > cwnd){
// 就不再把`snd_queue`的Segment移动到`snd_buf`
}
详细代码见kcp.go
func (kcp *KCP) flush()
// sliding window, controlled by snd_nxt && sna_una+cwnd
newSegsCount := 0
for k := range kcp.snd_queue {
if _itimediff(kcp.snd_nxt, kcp.snd_una+cwnd) >= 0 {
break
}
newseg := kcp.snd_queue[k]
newseg.conv = kcp.conv
newseg.cmd = IKCP_CMD_PUSH
newseg.sn = kcp.snd_nxt
kcp.snd_buf = append(kcp.snd_buf, newseg)
kcp.snd_nxt++
newSegsCount++
}
显然对于上图的情况,有cwnd是5,那么还可以从snd_queue中移动2个Segmen到snd_buf。
参考资料
1.KCP协议简介
后记
2023年5月12日

1. 拥塞窗口减小的情况
// cwnd update
if kcp.nocwnd == 0 {
// 1.1 发生快速重传的时候(丢包),进入 快速恢复 阶段
// update ssthresh
// rate halving, https://tools.ietf.org/html/rfc6937
if change > 0 {
inflight := kcp.snd_nxt - kcp.snd_una
kcp.ssthresh = inflight / 2
if kcp.ssthresh < IKCP_THRESH_MIN {
kcp.ssthresh = IKCP_THRESH_MIN
}
kcp.cwnd = kcp.ssthresh + resent
kcp.incr = kcp.cwnd * kcp.mss
}
// 1.2 如果出现超时重传的情况(丢包),重新进入 慢启动 阶段
// congestion control, https://tools.ietf.org/html/rfc5681
if lostSegs > 0 {
kcp.ssthresh = cwnd / 2
if kcp.ssthresh < IKCP_THRESH_MIN {
kcp.ssthresh = IKCP_THRESH_MIN
}
kcp.cwnd = 1
kcp.incr = kcp.mss
}
if kcp.cwnd < 1 {
kcp.cwnd = 1
kcp.incr = kcp.mss
}
}
2. 拥塞窗口增大的情况
每收到一个包,就尝试增大拥塞窗口
注意:拥塞窗口不能大于接收端,接收窗口的空闲大小
// cwnd update when packet arrived
if kcp.nocwnd == 0 {
if _itimediff(kcp.snd_una, snd_una) > 0 {
if kcp.cwnd < kcp.rmt_wnd {
mss := kcp.mss
if kcp.cwnd < kcp.ssthresh {
kcp.cwnd++
kcp.incr += mss
} else {
if kcp.incr < mss {
kcp.incr = mss
}
kcp.incr += (mss*mss)/kcp.incr + (mss / 16)
if (kcp.cwnd+1)*mss <= kcp.incr {
if mss > 0 {
kcp.cwnd = (kcp.incr + mss - 1) / mss
} else {
kcp.cwnd = kcp.incr + mss - 1
}
}
}
if kcp.cwnd > kcp.rmt_wnd {
kcp.cwnd = kcp.rmt_wnd
kcp.incr = kcp.rmt_wnd * mss
}
}
}
}
