读写锁为什么那么快?(2)
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1.前言
在上一篇文章读写锁为什么那么快?(1)中,萌叔探讨了读写锁提高程序性能的原因。这一篇文章,萌叔将聊聊读写锁面临的2个问题。并看看标准库的是如何实现。
2.几个问题
Q1: 如何避免写锁饥饿或者读锁饥饿问题?
我们知道读写锁的特性:同一时刻允许多个线程(协程)对共享资源进行读操作, 也就是说多个线程(协程)可以多次加读锁。那么会出现这样一种情况,读锁还没有被完全释放的情况(读锁计数器大于0),又有新的读操作请求加读锁。这样写协程永远无法加上写锁,将会一直阻塞。
A1:
标准库实际上引入某种类似排队的机制

如上图所示,协程G1、G2、G3、G4并发访问共享资源。它们请求加锁的顺序为矩形的左边沿,耗时为矩形块的长度
- t1时刻,G1加上了读锁,开始读操作
- t2时刻,G2也加上了读锁,进行读操作
- t3时刻,G3表示它要进行写操作
- t4时刻,G4也想加读锁,并且现在共享资源上施加的读锁还没有完全释放(需要到t5时刻才能释放),但是由于G3已经表示它需要加写锁了,所以G4将会阻塞
所以实际的运行顺序是

Q2: 如何确保加读锁时,成本尽可能的低?
读写锁最适用的情况是读多写少的场景,降低读锁的加锁和释放锁的开销,才能提高整体的吞吐能力。
A2:
- 读协程和写协程互斥仅用的到int32的整数
萌叔虽然也使用condition实现了读写锁,但由于
condition要求在判断条件是否满足,以及修改条件中相关联的变量时,都需要加互斥锁,因此萌叔的实现性能和标准库有一定的差距。 - 写协程和写协程的互斥靠的是标准库的互斥锁
3.代码
标准库的实现很巧妙,阅读有一定的难度。萌叔将对部分代码进行注释,并讲解。
package sync
import (
"internal/race"
"sync/atomic"
"unsafe"
)
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
/*
用于标识
1. 是否已经加了读锁或者写锁
2. 有多少个协程想加读锁(包含已经加上读锁的)
*/
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
/*
用于标识
写协程需要等待多少个读协程释放读锁才可以加上写锁
*/
readerWait int32 // number of departing readers
}
const rwmutexMaxReaders = 1 << 30
func (rw *RWMutex) RLock() {
...
/*
rw.readerCount+1 表示有读协程想加读锁
rw.readerCount < 0
就说明当前共享资源已经被加了写锁,或者排队的时候,读操作排在了某个写操作请求的后面,那么需要把自己挂起在rw.readerSem上
*/
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
...
}
func (rw *RWMutex) RUnlock() {
...
/*
rw.readerCount 小于0
说明有写协程想要加写锁
则需要唤醒写协程
*/
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
...
}
func (rw *RWMutex) rUnlockSlow(r int32) {
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
func (rw *RWMutex) Lock() {
...
// First, resolve competition with other writers.
/*
写协程和写协程的互斥依靠标准库的互斥锁
*/
rw.w.Lock()
// Announce to readers there is a pending writer.
/*
*/
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
/*
只要不等于0,就说明当前共享资源已经被加了读锁
那就把自己挂起在rw.writerSem上
*/
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
...
}
func (rw *RWMutex) Unlock() {
...
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
...
// Unblock blocked readers, if any.
/*
只要有读协程想要加读锁,就唤醒读协程
*/
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock()
...
}
Golang的标准库的读写锁实现具有某种偏向性(偏向读操作)。
在施加写锁期间,只要有读协程表示想加读锁,等到写锁释放时。不管是否有其它写协程想要加写锁。都会优先把共享资源,让给读协程。
我们来看个示例。

如上图所示,请求加锁的顺序为矩形的左边沿,耗时为矩形块的长度。
G5加写锁的请求先于G4加读锁的请求。但是由于G5被G3的互斥锁所阻塞,所以它没有修改rw.readerCount。但是G4会修改rw.readerCount,表示有协程想加读锁。所以等到G3释放写锁(过程中也会释放互斥锁rw.w) 唤醒了G4。G5会发现G4其实已经插队了,排在它的前面。
实际执行顺序为
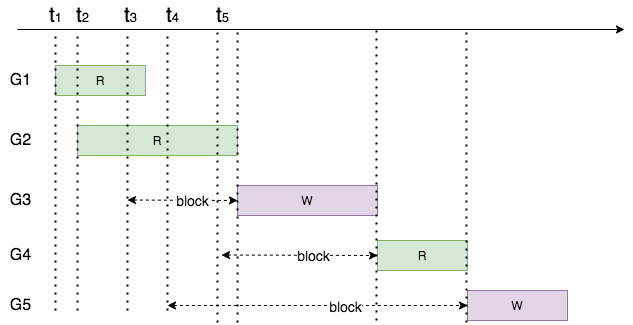
结论:标准库的读写锁实现对读操作有一定的偏向性
4. 总结
读写锁的有效代码还不到100行,但是隐藏的细节确非常多,推荐读者好好读读。