利用划分子集限制连接池的大小(1)
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 引言
我们的RCP系统中的每个客户端都会针对后端程序程序维持一个长连接发送请求。这些连接通常在客户端启动的时候就建立完成,并且保持活跃状态,不停地有请求通过它们,直到客户端终止。
每个连接都需要双方消耗一定数量的内存和CPU来维护。虽然这个消耗理论上很小,但是一旦数量多起来就可能变得很客观。
上面的两段话来自

在Golang中,每个连接除了接收和发送缓冲区,还会额外对应2个协程。在规模较大的服务中,浪费的资源是非常可观的。
在M个Client,N个Backend的场景中,一共需要建立M * N个连接。这种额外的负担不仅发生在Client端,同样影响会Backend。
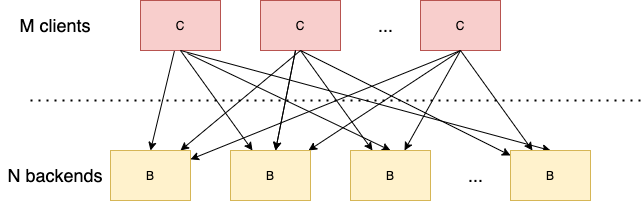
一个很朴素的想法是让每个Client只请求所有Backend的一部分。那么划分子集之后,是否会引起其它问题呢?
本文的重点是探讨使用Google给出的子集选择算法二:确定性算法,需要考虑的细节和注意事项。
2. 子集选择算法带来的思考
2.1 目标
当我们引入某个划分子集算法之后,我们担心的问题可能会有以下几个:
1) Backend的负载是否均衡
2) 当Backend集群发生变化(比如有实例宕机,或者进行滚动发布或者重启时,Client的连接池是否有大量的连接需要创建或者销毁
3) 当Backend集群发生变化(比如有实例宕机,或者进行滚动发布或者重启时,Client的请求时的错误率相比没有划分子集时,是否会变大
2.2 子集选择算法
2.2.1 随机选择
先来看看随机算法是否可行, 假定
clientSize=50
backendSize=100
subsetSize=50
生成图片用ggplot2
library(ggplot2)
data <- read.table("/tmp/datafile.csv",header=TRUE, sep=",")
ggplot(data, aes(X, Y)) + geom_bar(stat = 'identity')
subset/random/random.go
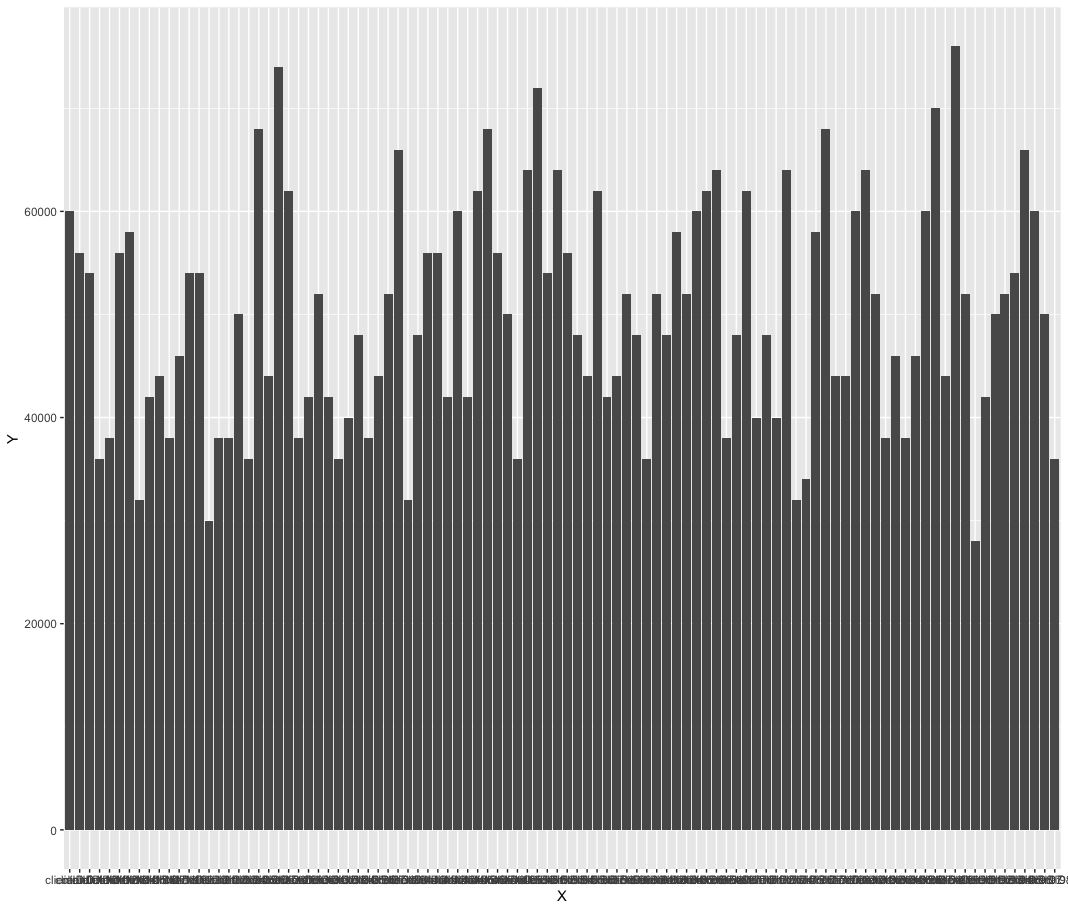
显然随机算法的效果不行
2.2.2 确定性算法
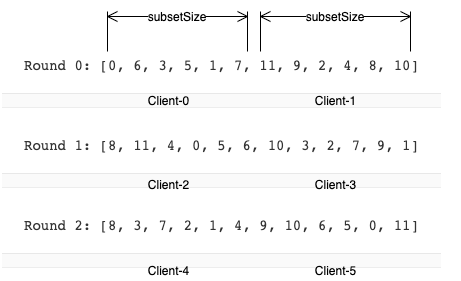
func Subset(backends []string, clientID, subsetSize int) []string {
subsetCount := len(backends) / subsetSize
// Group clients into rounds; each round uses the same shuffled list:
round := clientID / subsetCount
r := rand.New(rand.NewSource(int64(round)))
r.Shuffle(len(backends), func(i, j int) { backends[i], backends[j] = backends[j], backends[i] })
// The subset id corresponding to the current client:
subsetID := clientID % subsetCount
start := subsetID * subsetSize
return backends[start : start+subsetSize]
}
只有短短几行,我们来下效果
subset/certainty1/verify.go

负载非常均衡
但是这里有2个前提条件
- clientID必须连续
- backendSize要是subsetSize的整数倍,或者接近整数倍
看2个反例
反例1
网上有说通过hash算法生成clientID,我们来看下效果
subset/certainty2/verify.go
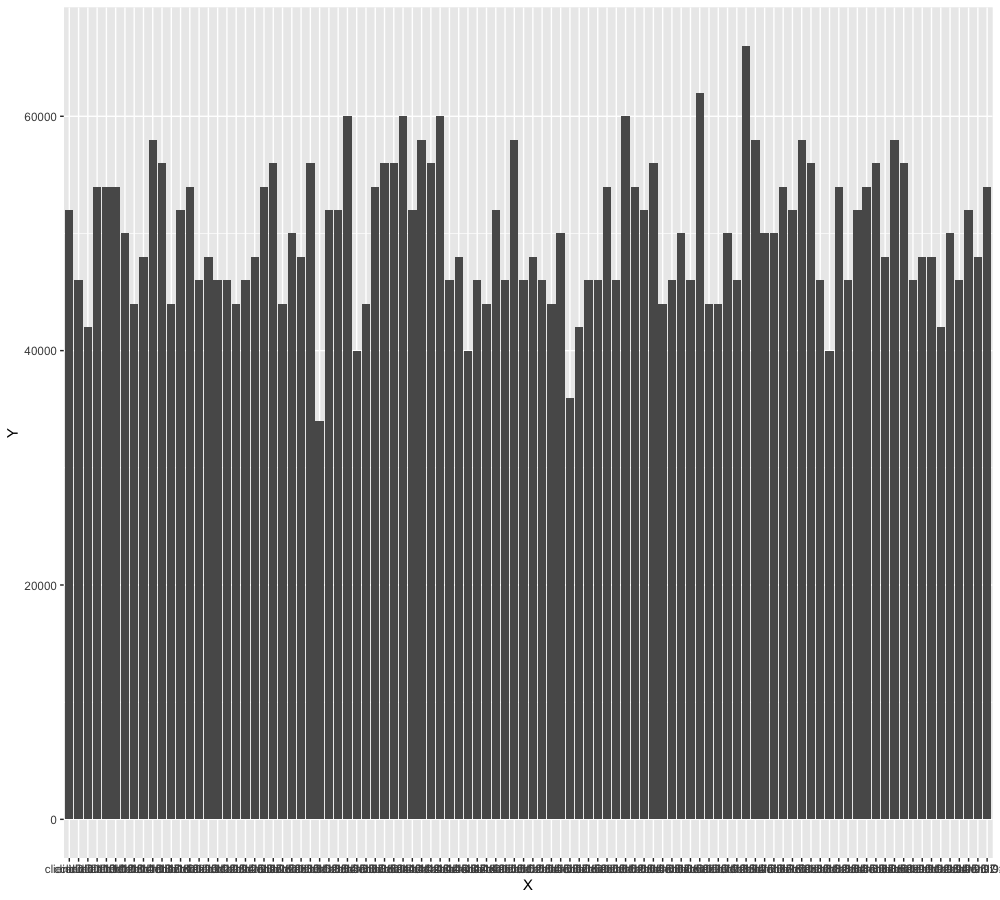
反例2
在这个例子中,我们来看下backendSize如果不是subsetSize的整数倍
subset/certainty3/verify.go
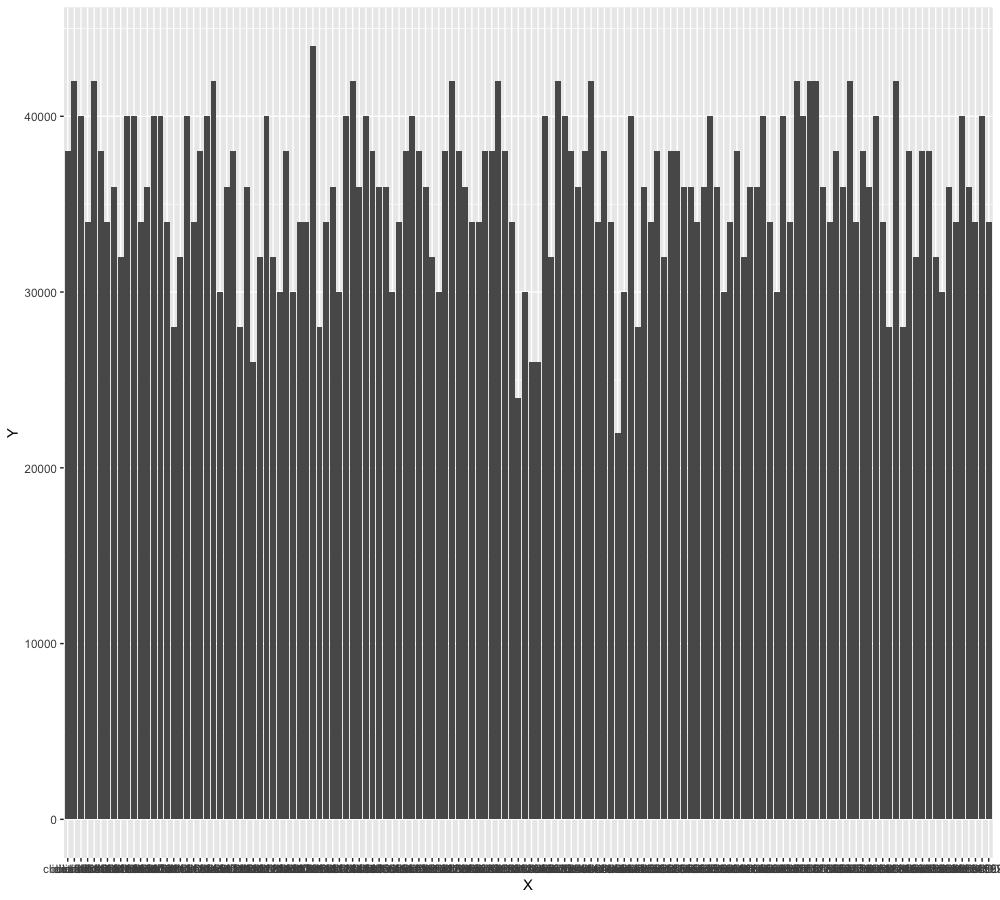
如果backendSize不是subsetSize的整数倍,则会有一部分backend无法被client覆盖,backend的负载不能完全均衡。
参考资料

赞,好文