RocketMQ架构设计中的”暴力美学”(2)-故障处理
本文基于rocketmq-all-4.8.0
1.引言
人们在潜意识里,总会觉得复杂且精巧的东西是好东西。但是这个复杂这个词在软件架构设计中,却不一定是好事情。
因为过于精巧和复杂的系统往往意味着系统更难以维护,出现问题后,故障更难排查。
萌叔在阅读和分享RocketMQ的过程中, 发现它有很多设计非常的简单粗暴,堪称”暴力美学”的典范,
同时又给人眼前一亮的感觉(还能这么玩)。
2.故障处理
在介绍故障处理机制时,我们假定一个场景
2.1 架构
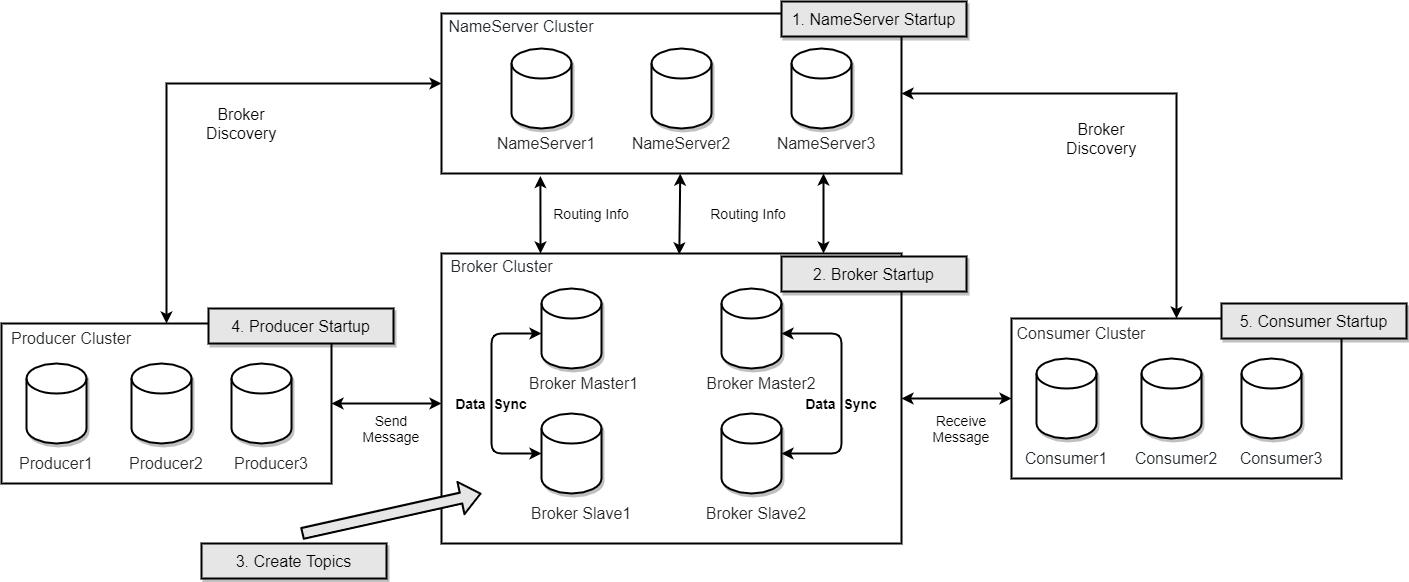
假定broker有2组
group1
Master1和Slave1
group2
Master2和Slave2
2.2 故障发生
故障发生前,萌叔创建了1个topic,指定分片数为4
mqadmin updateTopic -n <namesrvAddr> -c <clusterName> -t myTopic -q 4这里需要强调一下,这里指定的4个分片,并不是全局4个分片,而是每个broker有4个分片,情况如下图。
此时 Topic路由信息形如:
{
"OrderTopicConf": "",
"queueDatas": [{
"brokerName": "group1",
"readQueueNums": 4,
"writeQueueNums": 4,
"perm": 6, // 可读可写
"topicSynFlag": 0
}, {
"brokerName": "group2",
"readQueueNums": 4,
"writeQueueNums": 4,
"perm": 6, // 可读可写
"topicSynFlag": 0
}],
"brokerDatas": [{
"cluster": "Default_Cluster",
"brokerName": "group1",
"brokerAddrs": {
"0": "192.168.12.123:10911", // master
"1": "192.168.12.127:10911" // slave
}
}, {
"cluster": "Default_Cluster",
"brokerName": "group2",
"brokerAddrs": {
"0": "192.168.12.220:10911",
"1": "192.168.12.12:10911"
}
}]
}生产者消息路由策略:Round Robin
消费者消息路由策略:AllocateByAveragely
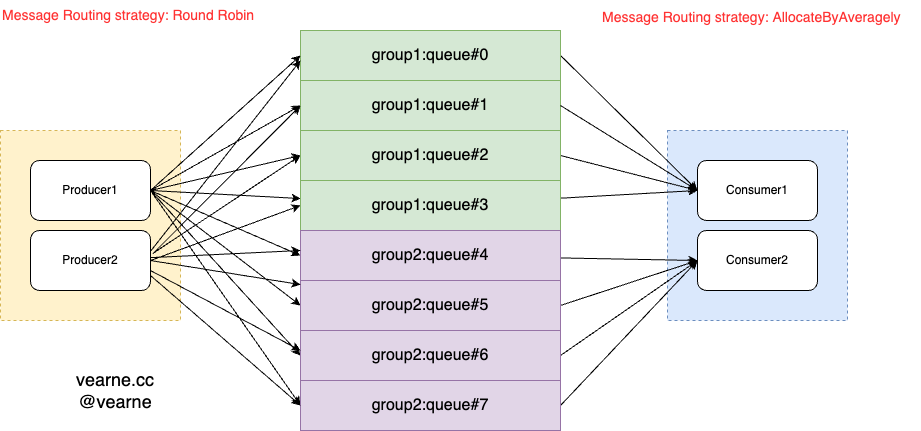
假定group1的Master1实例发生异常, 情况变为下图
- 1)group1的Master1实例发生异常
- 2)Master1与NameServer的心跳超时,NameServer感知到Master1的异常
- 3)Producer感知到Topic路由信息发生变化,此时group1只能读取,无法写入
- 4)Master1出现异常后,Consumer1仍然能从Salve1将之前queue#0、queue#1、queue#2、queue#3上未被消费的message消费掉
Topic路由信息形如:{ "OrderTopicConf": "", "queueDatas": [{ "brokerName": "group1", "readQueueNums": 4, "writeQueueNums": 0, "perm": 2, // 只读 "topicSynFlag": 0 }, { "brokerName": "group2", "readQueueNums": 4, "writeQueueNums": 4, "perm": 6, // 可读可写 "topicSynFlag": 0 }], "brokerDatas": [{ "cluster": "Default_Cluster", "brokerName": "group1", "brokerAddrs": { "0": "192.168.12.123:10911", // master "1": "192.168.12.127:10911" // slave } }, { "cluster": "Default_Cluster", "brokerName": "group2", "brokerAddrs": { "0": "192.168.12.220:10911", "1": "192.168.12.12:10911" } }] }注意:
在 Apache RocketMQ 中,Slave 节点不能被自动提升为 Master 节点。
RocketMQ 的设计中,Master 和 Slave 有着明确的角色分工和职责,
不支持 Slave 自动提升为 Master 的机制。
原因及设计哲学
Master-Slave 角色分工:
- Master 节点负责处理消息的生产和消费请求,通常是唯一能够接收写请求的节点。
- Slave 节点作为 Master 的备份,通常用于读取操作和故障恢复。Slave 仅仅是 Master 数据的复制体。
一致性与复杂性:
- 如果 Slave 被提升为 Master,会涉及到消息的顺序性、一致性和故障恢复等复杂问题。
- RocketMQ 选择了简单而明确的主从架构,即使 Master 宕机了,
也不会自动提升 Slave 来接替其角色,而是需要管理员进行人工干预。
2.2 故障恢复与扩容
细心的读者可能已经发现, Master1发生故障以后,group1无法写入,如果group2的Master2也宕机,
myTopic就完全无法写入了。为了提高可用性
- 增加一组机器group3(包含Master3和Slave3)
- 一段时间之后,待group1上消息都消费完毕,将group1完全下线
注意:
myTopic在group3上是没有分片的,需要手动创建
mqadmin updateTopic -n <namesrvAddr> -c <clusterName> -b 192.168.12.55:10911 -t myTopic -q 4其中-b参数指定broker的地址
3. 总结
如果和kafka对比,读者可能会发现Rocketmq 啥啥都没有,但是它带来的好处也是非常明显的。
它使得集群维护和排查问题变得比较简单,特别是针对海量数据处理和大规模集群的维护有很有意义。
"大道至简,大巧不工"
作者: vearne
文章标题: RocketMQ架构设计中的”暴力美学”(2)-故障处理
发表时间: 2024年8月7日
文章链接: https://vearne.cc/archives/40155
版权说明: CC BY-NC-ND 4.0 DEED
