一文了解RAG(检索增强型生成)
在这篇文章中,萌叔将介绍RAG技术。
将它与传统的搜索引擎进行对比,并介绍一个完整的RAG实现--lightRAG,详述其技术细节。
1. 传统搜索
传统搜索通常基于倒排索引来进行搜索
1.1 倒排索引
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,
是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
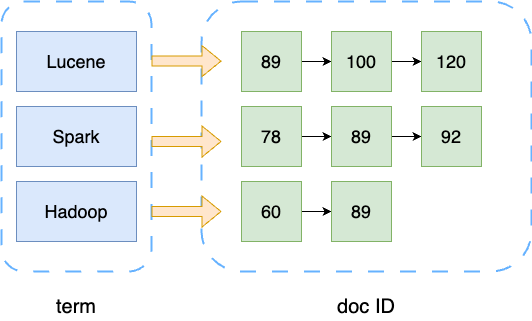
倒排索引是Term到DocID的映射。
1.2 搜索语句示例
Lucene针对某个字段进行搜索样例
title:hello world就意味着,搜索title为hello,或者包含title关键字的文档
伪代码形如
doc.title contains "hello" OR doc.title contains "world"假定
"hello"-> [1, 5, 8]
"world"-> [5, 8, 10, 12]
然后搜索引擎对2个doc ID集合的求并集,并对所有文档进行打分,选出分数最高的前N个文档。
2. RAG
RAG (检索增强生成) 是一种人工智能技术,它结合了信息检索和生成式模型的功能,
以提高生成文本的准确性和相关性。 RAG 先从外部知识库中检索相关信息,然后结合这些信息,使用生成式模型,
生成更准确、更有上下文相关的文本。
提到RAG,需要先聊一聊Embedding models
2.1 Embedding models
2.1.1 高维向量表征文本
嵌入式模型,可以把一段文本转换为纯数值的高维向量
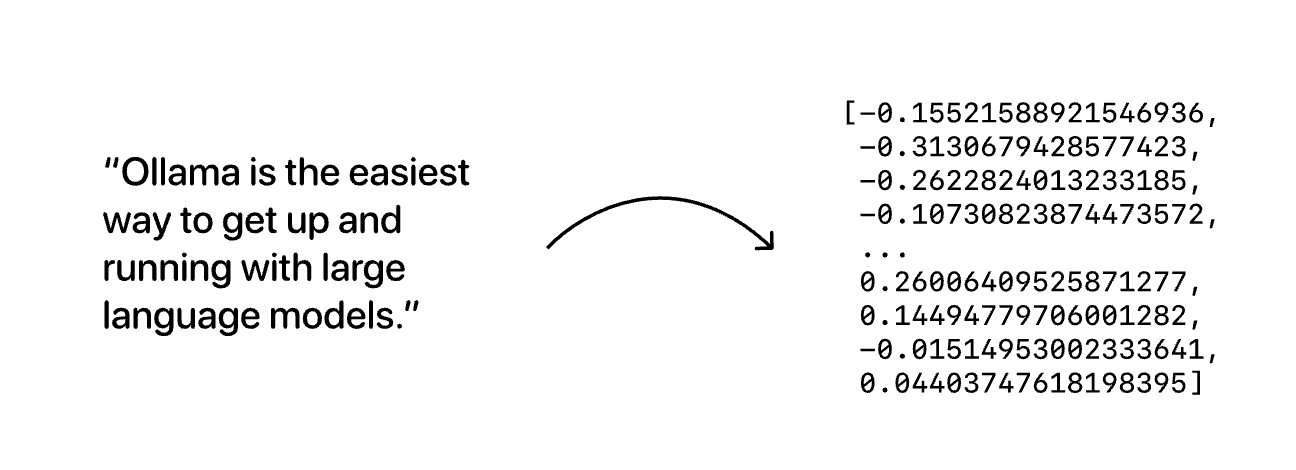
通过嵌入模型(如bge-m3)将文本转换为1024维的数值向量,这个向量包含了文本的语义特征
curl --location 'http://192.168.100.2:21434/api/embed' \
--header 'Content-Type: application/json' \
--data '{
"model": "bge-m3:latest",
"input": "这个故事的主题是什么?"
}'2.1.2 向量距离反映语义相似度
当两个向量在向量空间中的距离越近(通常用余弦相似度或欧氏距离衡量) 说明它们对应的文本在语义上越相似
例如"猫"和"猫咪"的向量会比"猫"和"汽车"的向量更接近
高维向量可以使用专门的向量数据库存储和检索。
2.1.3 常见向量数据库一览
| 名称 | 是否开源 | 社区影响力 | 编程语言 | 核心特性 |
|---|---|---|---|---|
| Pinecone | 否 | 未知 | 向量存储与检索全托管 | |
| weaviate | 是 | 13.7k star | Go | 同时支持向量与对象的存储、支持向量检索与结构化过滤、具备主流模式成熟的使用案例。高速、灵活,不仅仅具备向量检索,还会支持推荐、总结等能力 |
| qdrant | 是 | 24.3k star | Rust | 向量存储与检索、云原生、分布式、支持过滤、丰富的数据类型、WAL日志写入 |
| milvus | 是 | 35.6k star | Go | 极高的检索性能: 万亿矢量数据集的毫秒级搜索非结构化数据的极简管理丰富的API跨平台实时搜索和分析可靠;具有很高的容灾与故障转移能力高度可拓展与弹性支持混合检索统一的Lambda架构社区支持、行业认可 |
| Chroma | 是 | 20.7k star | Python | 轻量、内存级 |
3.lightRAG 实现
https://github.com/HKUDS/LightRAG
"talk is cheap show me the code" – Linus Torvalds
这一部分将介绍一个开源的RAG实现LightRAG。RAG通常被用来构建知识库, 萌叔将从使用和细节上2方面来介绍LightRAG。
对代码有兴趣的读者也可也阅读参考资料4.深度解析比微软的GraphRAG简洁很多的LightRAG,一看就懂
LightRAG可以使用下面的命令直接启动
lightrag-server此服务其实包含1)API服务器 + 2)WebUI
API详情见 http://localhost:9621/webui/#/
由于是知识库,那么必然我们需要先创建知识库,为知识库添加知识
3.1 提交文件,针对知识构建索引
提交的文件,会被异步任务处理。
step1: 把文件切分成chunk

默认情况(函数chunking_by_token_size),文件会被按照固定的token size切割成chunk, 为防止某些entity出现在chunk的交界处,chunk会有一定的重叠。
step2: 将chunk + prompt 提交给大语言模型,进行知识抽取
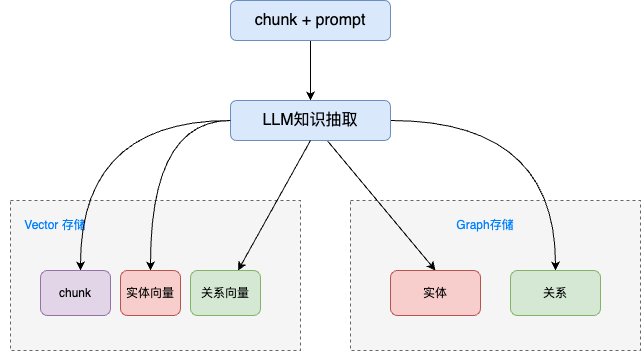
从上图可以看到,从chunk中,抽取了实体和关系, 为了存储实体和关系,引入了向量数据库和图数据库
LightRAG 默认使用的向量数据库是 Nano Vector,默认使用的图数据库是 NetworkX。
step2使用大语言模型,有一定的开销。萌叔测试官方的示例book.txt 188K,花费大约2元人民币。
3.2 检索知识,结合知识使用大模型,生成对应的回答。
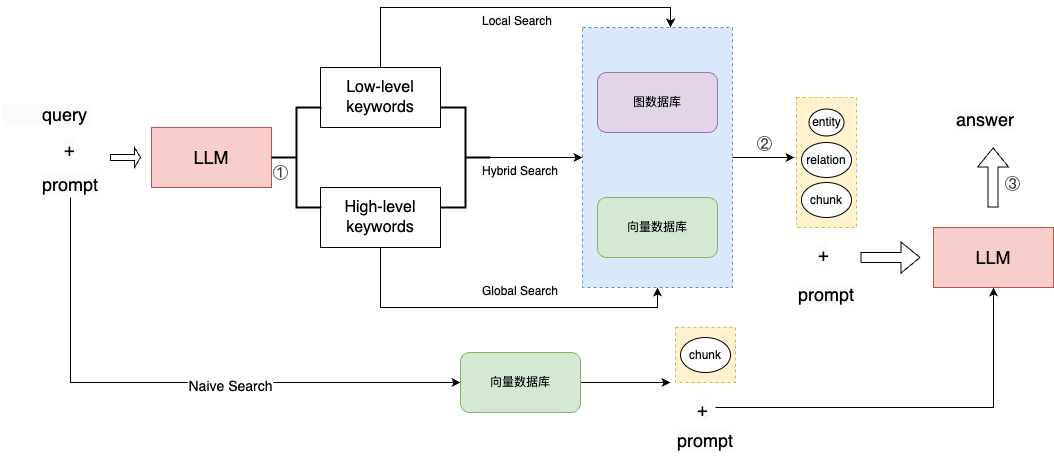
① 针对用户的的查询语句生成高阶和低阶的关键词
下面是某个查询得到的关键词
2025-05-09 18:58:42,458 - lightrag - DEBUG - High-level keywords: ['Character analysis', 'Literature', 'Social themes']
2025-05-09 18:58:42,459 - lightrag - DEBUG - Low-level keywords: ['Bob Cratchit', 'A Christmas Carol', 'Charles Dickens', 'Scrooge', 'Victorian era']② 根据查询类型从向量数据库和图数据库中提取数据
下面是不同查询类型提取的数据差异
# local
INFO: Local query uses 10 entites, 127 relations, 3 chunks
# global
INFO: Global query uses 11 entites, 10 relations, 3 chunks
# hybrid
INFO: Local query uses 10 entites, 127 relations, 3 chunks
INFO: Global query uses 12 entites, 10 relations, 3 chunksLocal search针对的是节点以及与节点相关的边,包含节点、边对应的实际数据Global search针对的是边,包含边对应的实际数据Hybrid search同时包含Local search和Global search的结果Naive search只使用原始的chunk
有个重要的参数topK,用于控制entity或者relation的数量
③ 根据检索到的数据和提示词生成合适的回答
3. 总结
透过RAG技术,我们可以清晰地看到大语言模型如何颠覆传统的信息检索和知识问答领域,
通过结合检索与生成的优势,实现了更准确、更智能的知识获取与内容生成。
参考资料
1.LIGHTRAG: SIMPLE AND FAST
RETRIEVAL-AUGMENTED GENERATION
2.Embedding models
3.GraphRAG
4.深度解析比微软的GraphRAG简洁很多的LightRAG,一看就懂
5.Lucene查询语法详解
6.词向量 Word2Vec
作者: vearne
文章标题: 一文了解RAG(检索增强型生成)
发表时间: 2025年6月28日
文章链接: https://vearne.cc/archives/40283
版权说明: CC BY-NC-ND 4.0 DEED
