聊聊RAFT的一个实现(4)–NOPCommand
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 前言
在我的文章聊聊RAFT的一个实现(3) 我曾经提到NOPCommand也是一种LogEntry,它会在集群中被分发。那么它有什么作用呢?
2. NOPCommand
我们依然使用raft paper
5.4 Safety 图8来说明这个问题
2.1 场景1
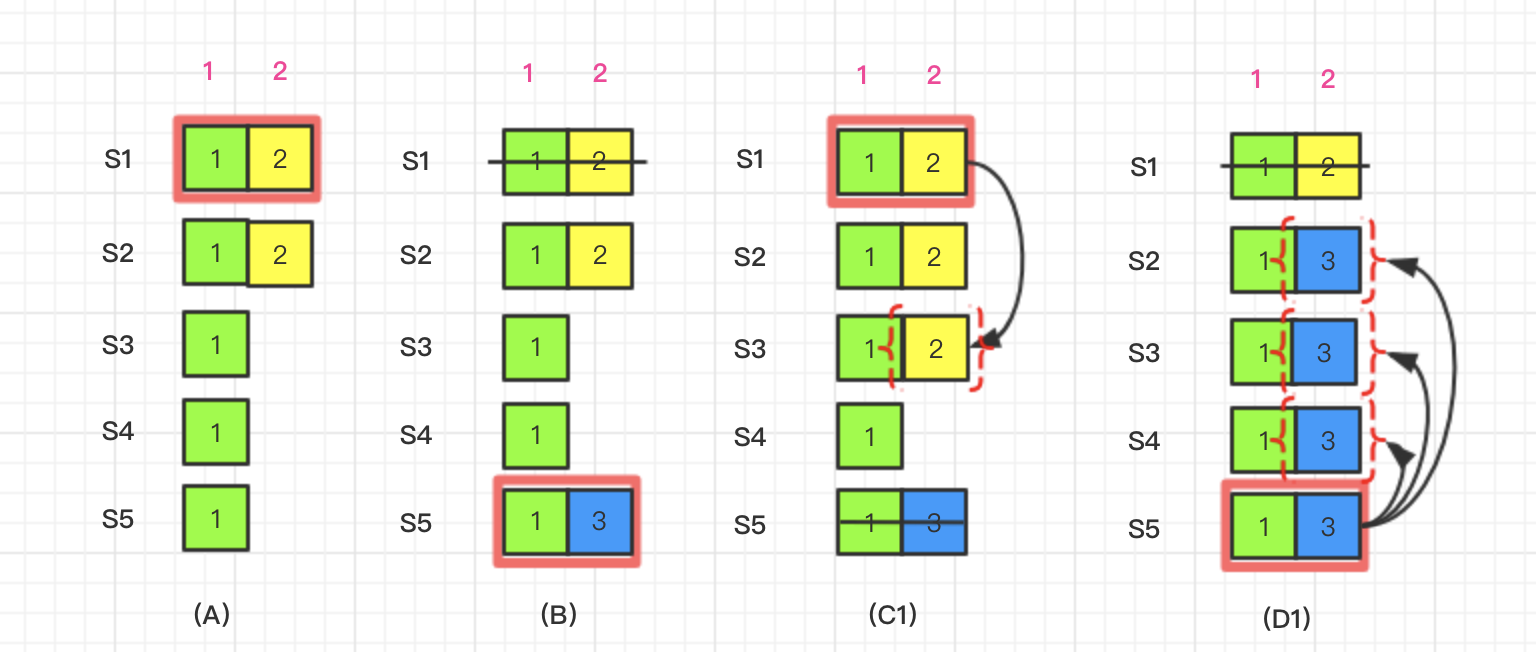
如图所示,集群中有S1 ~ S5,5个节点,在时间点(A),S1是leader, 它接收到外部的指令,生成logIndex 2的日志,并复制到S2。在时间点(B)S1奔溃了,S5在term 3通过S3、S4和自己的选票赢得选举,称为leader。它从客户端接收到一条不一样的日志条目放在logIndex 2。然后到时间点(C1), S5又崩溃了;S1重新启动,被选举为leader, 开始复制日志LogEntry{Term:2, Index:2} 到S3, 此时已经达到了提交点。LogEntry{Term:2, Index:2} 已经被复制到majority,可以向状态机中写入数据了。但是接下来时间点(D1) S1可能再次崩溃,S5重新启动,S5可以重新被选举成功(通过S3、S4以及它自己的选票)。然后复制日志LogEntry{Term:3, Index:2}到S2、S3、S4。

如果事情进展按上面的情况发生, 那么显然违反了raft论文所要求
Leader Completeness和State Machine Safety
领导人完全特性--如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中(5.4 节)
状态机安全特性--如果一个领导人已经在给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会提交一个不同的日志(5.4.3 节)
2.2 场景2
为了解决这个问题, raft引入了空命令NOPCommand
Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server;
一旦选举为leader, leader应该立马发送一个空命令给其它所有节点。
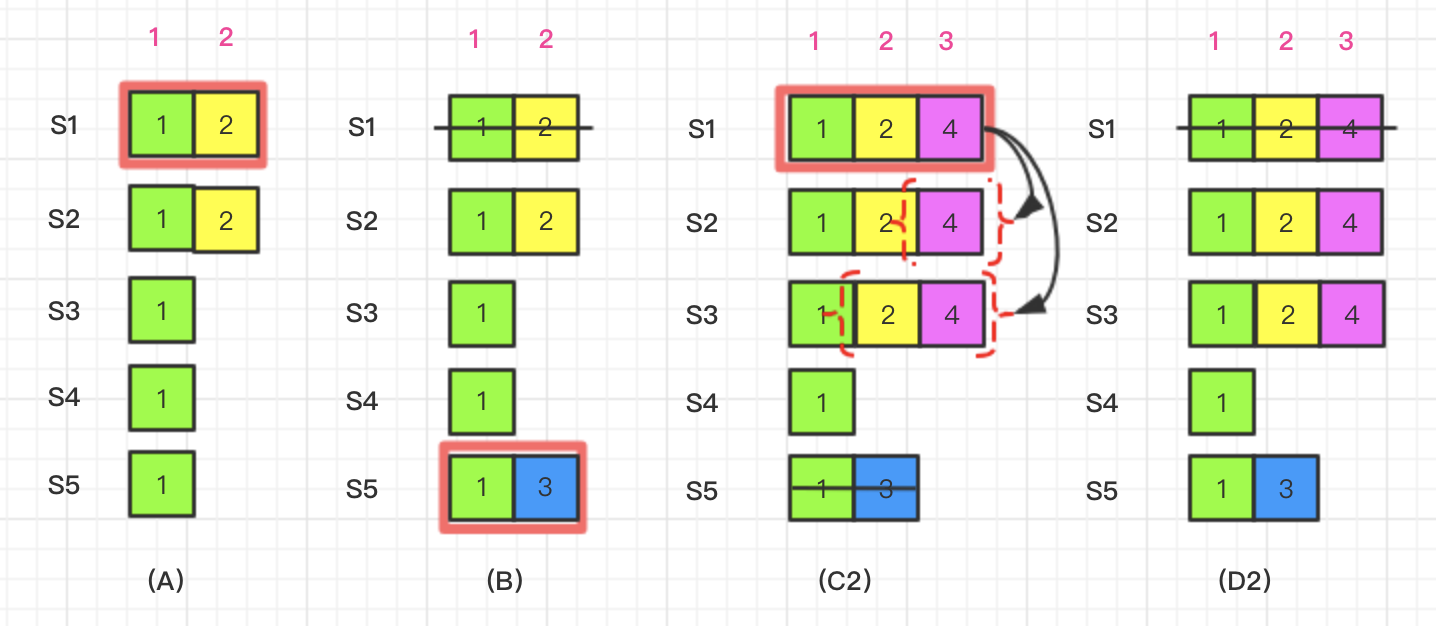
我们看看有了这个空命令后,是否还会出现已提交的日志被覆盖的情况。在时间点(C2), S5崩溃,S1重启;S1通过S2、S3以及它自己的选票当选为leader。它与S2、S3完成了日志同步, 此时又达到了提交点,commitIndex是4。
然后在时间点(D2)S1再次崩溃。此时谁能被选为leader, 当选的只能是S2和S3。被提交的日志LogEntry{Term:2, Index:2}和LogEntry{Term:4, Index:3} 得到了保留。
2.3 场景3
那么有没有可能是这样
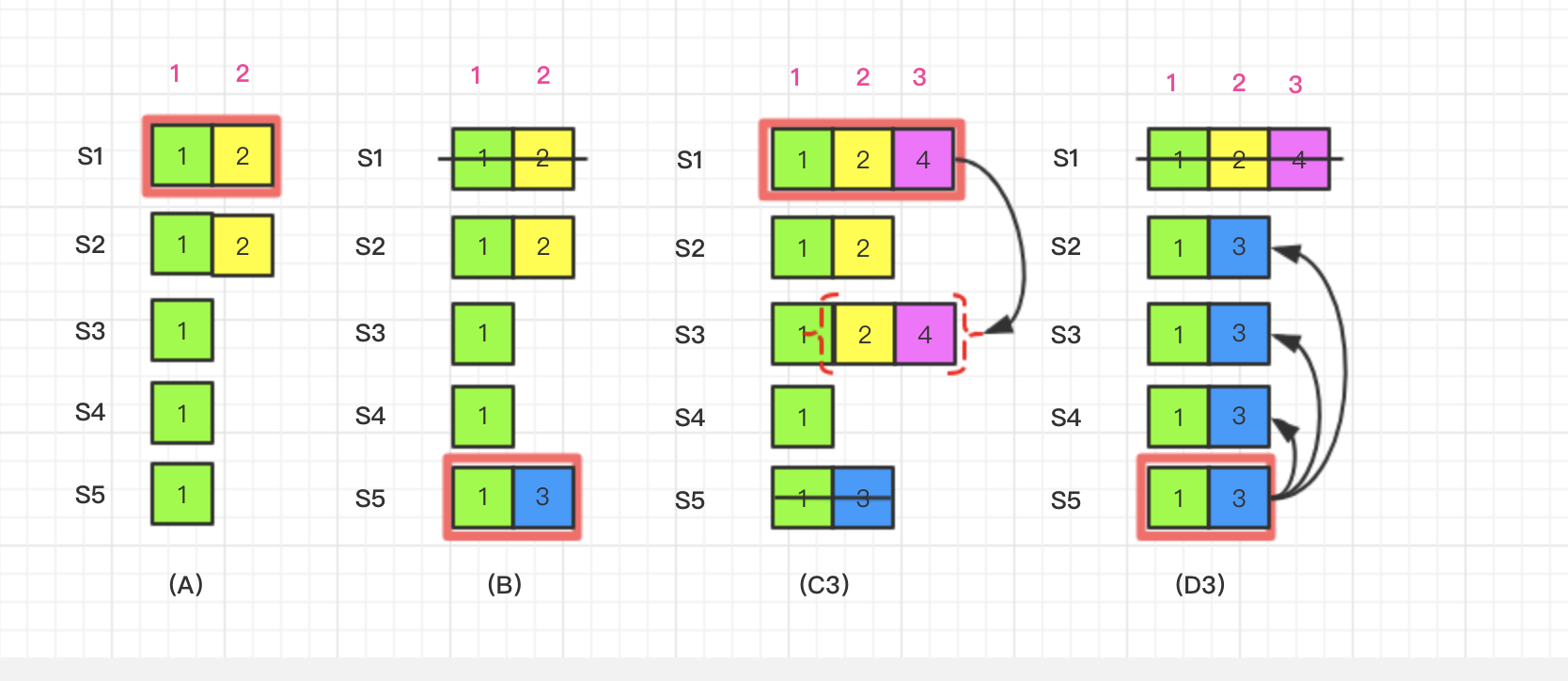
在时间点(C3), S5崩溃,S1重启;S1通过S2、S3以及它自己的选票当选为leader。它仅仅只与S3完成了日志同步。此时似乎也达到了日志提交点。如果下一个时间点(D3), S1崩溃,S5重启;S5能够通过S2、S4以及它自己的选票当选。然后S5复制日志LogEntry{Term:3, Index:2} 到S2、S3、S4
在goraft的实际实现中,在时间点(C3), 集群还没有达到提交点,虽然此时LogEntry{Term:2, Index:2}已经存在于S1、S2、S3。但goraft要求新当选的leader至少与majority的节点成功完成日志同步,且LogEntry已经存在于绝大节点才算到达了提交点。因此对于场景3所描述的情况,属于未提交。场景3属于正常情况。
// Processes the "append entries" response from the peer. This is only
// processed when the server is a leader. Responses received during other
// states are dropped.
func (s *server) processAppendEntriesResponse(resp *AppendEntriesResponse) {
// If we find a higher term then change to a follower and exit.
if resp.Term() > s.Term() {
s.updateCurrentTerm(resp.Term(), "")
return
}
// panic response if it's not successful.
if !resp.Success() {
return
}
// if one peer successfully append a log from the leader term,
// we add it to the synced list
if resp.append == true { // ***注意***这里
s.syncedPeer[resp.peer] = true
}
// Increment the commit count to make sure we have a quorum before committing.
if len(s.syncedPeer) < s.QuorumSize() { // ***注意***这里
return
}
// 如果没有与多数节点成功进行同步,不会commit日志
// Determine the committed index that a majority has.
var indices []uint64
indices = append(indices, s.log.currentIndex())
for _, peer := range s.peers {
indices = append(indices, peer.getPrevLogIndex())
}
sort.Sort(sort.Reverse(uint64Slice(indices)))
// We can commit up to the index which the majority of the members have appended.
commitIndex := indices[s.QuorumSize()-1]
committedIndex := s.log.commitIndex
if commitIndex > committedIndex {
// leader needs to do a fsync before committing log entries
s.log.sync()
s.log.setCommitIndex(commitIndex)
s.debugln("commit index ", commitIndex)
}
}
3. goraft实现的一点瑕疵
- 在目前goraft的实现中,对图(D1)的日志擦除,它根本也没有实现,只会提示"log.truncate.termMismatch", 拒绝
leader发出的AppendEntriesRequest。所以作者也说了不要把goraft用于生产环境。 - 另外旧的
leader崩溃,到新的leader选出,此时最有可能出现集群各个节点状态不一致。此时执行NOPCommand后,应当立马触发一次心跳,而不应当等待heartbeatInterval到期,再触发心跳。
4. 参考资料
- In Search of an Understandable Consensus Algorithm
- In Search of an Understandable Consensus Algorithm 中文翻译
- Raft协议精解
- 聊聊RAFT的一个实现(3)–COMMIT
