读写锁为什么那么快?(1)
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1.实验
首先让我们来看一组单元测试结果,看看互斥锁和读写锁在不同场景下的表现。
这里使用了极客兔兔的《Go 语言高性能编程》中的case,在此特别鸣谢
vearne/golab
BenchmarkReadMore-4 1 1195229024 ns/op
BenchmarkReadMoreRW-4 9 122810085 ns/op
BenchmarkReadMoreMyRW-4 8 145523134 ns/op
BenchmarkWriteMore-4 1 1296582090 ns/op
BenchmarkWriteMoreRW-4 1 1194438009 ns/op
BenchmarkWriteMoreMyRW-4 1 1247918412 ns/op
BenchmarkEqual-4 1 1344248968 ns/op
BenchmarkEqualRW-4 2 661674534 ns/op
BenchmarkEqualMyRW-4 2 685353924 ns/op
1.1 读写量 9:1
读多写少
| 方法 | 说明 | 耗时(ms) | 备注 |
|---|---|---|---|
| BenchmarkReadMore | 标准库-互斥锁 | 1195 | |
| BenchmarkReadMoreRW | 标准库-读写锁 | 122 | |
| BenchmarkReadMoreMyRW | 萌叔实现的读写锁 | 145 | 传送门: vearne/second-realize/rwlock |
1.2 读写量 1:9
写多读少
| 方法 | 说明 | 耗时(ms) | 备注 |
|---|---|---|---|
| BenchmarkWriteMore | 标准库-互斥锁 | 1296 | |
| BenchmarkWriteMoreRW | 标准库-读写锁 | 1194 | |
| BenchmarkWriteMoreMyRW | 萌叔实现的读写锁 | 1247 | 传送门: vearne/second-realize/rwlock |
1.3 读写量 1:1
读写数量相同
| 方法 | 说明 | 耗时(ms) | 备注 |
|---|---|---|---|
| BenchmarkEqual | 标准库-互斥锁 | 1344 | |
| BenchmarkEqualRW | 标准库-读写锁 | 661 | |
| BenchmarkEqualMyRW | 萌叔实现的读写锁 | 685 | 传送门: vearne/second-realize/rwlock |
1.4 结果
从实验结果看,
1)在读多写少(9:1)的情况下,使用读写锁的情况 性能比使用互斥锁的情况高出1个数量级。
2)在读少写多(1:9)的情况下,使用读写锁的情况 与使用互斥锁的情况相比,性能接近。
2)在读写数量相同的(5:5)的情况下,使用读写锁的情况 比使用互斥锁的情况, 性能提升了1倍。
2. 为什么?
回顾一下读写锁的特性。
同一时刻允许多个线程(协程)对共享资源进行读操作;同一时刻只允许一个线程(协程)对共享资源进行写操作;当进行写操作时,同一时刻其他线程(协程)的读操作会被阻塞;当进行读操作时,同一时刻所有线程(协程)的写操作会被阻塞。
假设读写操作对共享资源的访问顺序为
2.1 Case 1
rrrwrrrw
使用读写锁
图1
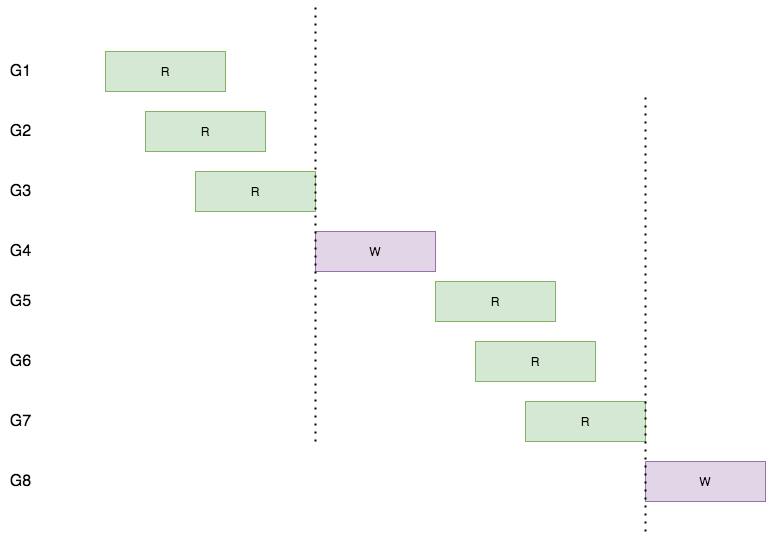
G1、G2、G3的读操作是并发的
G5、G6、G7的读操作也是并发的
使用互斥锁
图2
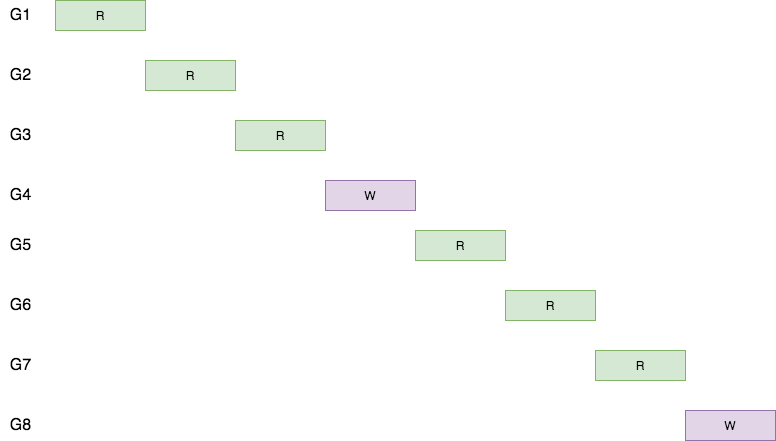
使用互斥锁,所有的读写操作变成了串行。
从图1和图2的对比来看,很容易得出结论,读写锁对性能的提升,主要是因为读写锁提高了协程的并发粒度,因此减少了总的吞吐时间。
Q1: 如果调整读写操作对共享资源的访问顺序,能够获得更大的并发粒度,从而提升总的吞吐时间。
2.2 Case 2
调整case1的读写操作顺序
rrrwrrrw -> rrrrrrww
图3
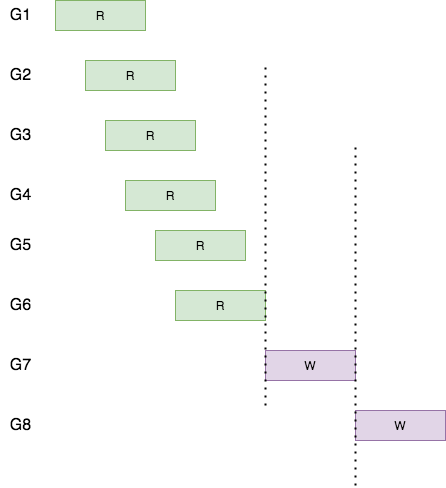
A1: 从图上可以很明显的看出,调整读写顺序可以增大协程的并发粒度,必然可以减少了总的吞吐时间。
注 实际上满足这种条件的case不是太好造,
笔者实现的的
vearne/second-realize/rwlock 可以通过参数调节这个过程。
3. 总结
本文探讨了读写锁性能优于互斥锁的原因,下一篇文章将探讨,读写锁面临的几个问题,以及标准库是如何解决的。
参考资料
请我喝瓶饮料
