玩转consul(3)–大规模部署的性能开销定量分析
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 引言
今天有朋友问萌叔,consul能否在大规模生产环境下进行应用。场景是总计大约10w+台机器,分为3 ~ 4个机房,单个机房最多3w万+机器。这个问题大的,可把萌叔吓了跳,部门里面consul集群的规模也就是1k+, 还分好几个机房。
不过他的问题确实也让我十分好奇,consul是否有能力支撑这么规模,我决定针对每个可能性能瓶颈进行定量分析
2. 分析
在进行分析前,我们来看看可能遇到瓶颈有哪些?
下图是consul在多DC情况下的体系架构图
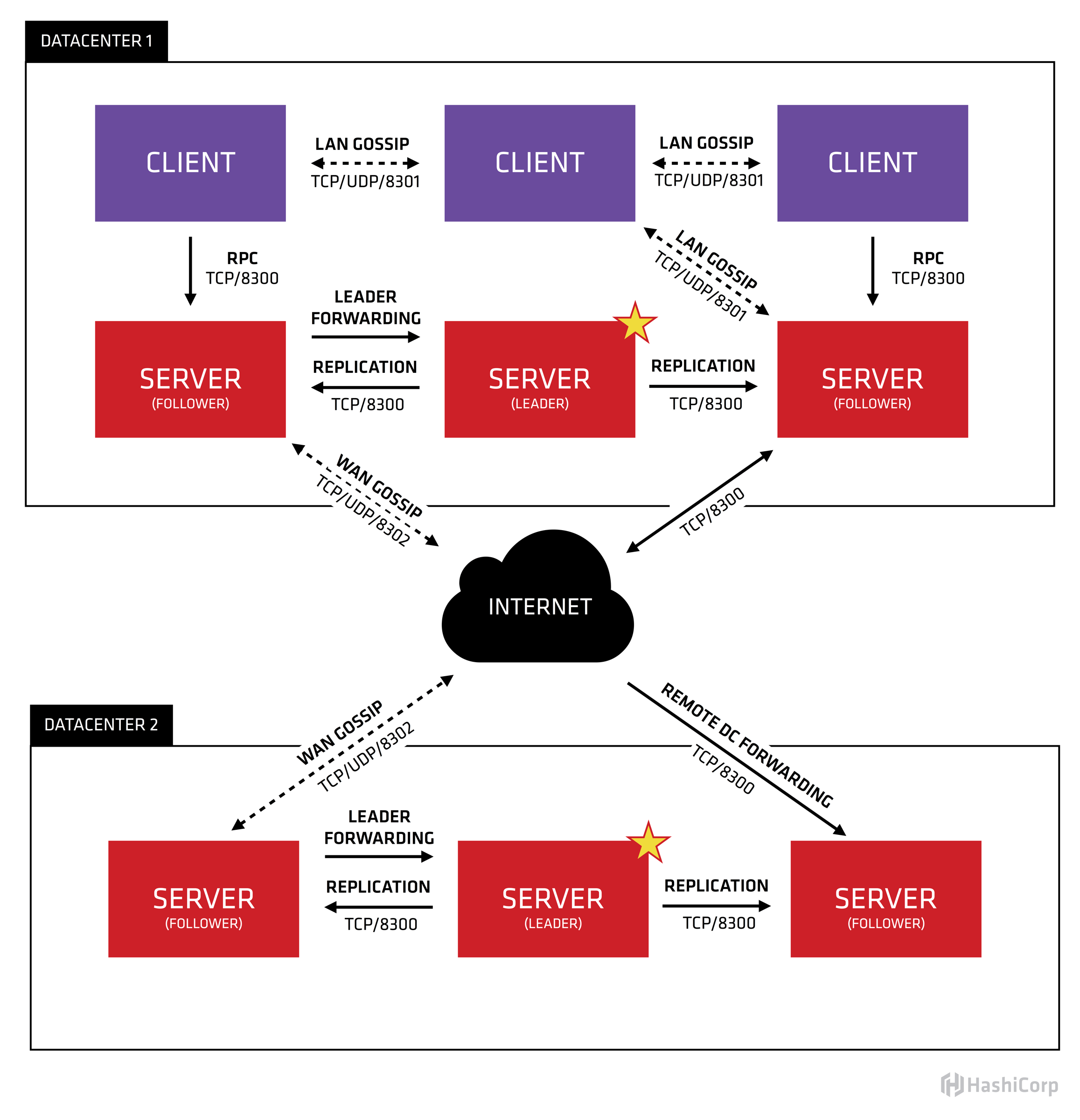
2.1 明确一些概念
- consul agent分2种模式server模式和client模式。在每个机房
consul server(以下简称为server)会部署3 ~ 5台, 其余的consul节点都是consul client(以下简称为server)。
server的数量不宜过多,否则选主的速度会变慢 - 数据(包括kv数据,service信息,node信息)都是分机房存储的,由所在机房的
server负责。如果需要请求其它机房的数据,则server会将请求转发到对应的机房。
比如dc1的某个应用app1想要获取dc2中key "hello"对应的值
过程如下
app1 --> client --> server(dc1) --> server(dc2)
如果读者仔细观察会发现,consul中,很多api都是可以加上dc参数的
consul kv get hello -datacenter dc2
- 每个dc的所有
server构成一个raft集群,client不参与选主。注意上图的leader和follower标识。 - 单个机房内部consul节点之间有gossip(端口8301)
- 机房与机房之间
server节点之间有gossip(端口8302)
2.2 可能的瓶颈
2.2.1 client对server的RPC请求
client使用server的TCP/8300端口发起RPC请求, 管理service、kv都要通过这个端口,它们之间是长连接。
1个机房如果有3w+机器,则client和server至少要建立3w+长连接。
不过萌叔观察了一下,3w+长连接是相对均匀的分布在多个server上的,也就是说如果你有6台consul server, 那么每个server最多处理5k个长连接。还是可以接收的。
对于server的处理能力我简单压测了一下。大约是15k qps
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
4核CPU 8G内存
╰─$ wrk -t10 -c500 -d30s http://dev2:8500/v1/health/service/consul
Running 30s test @ http://dev2:8500/v1/health/service/consul
10 threads and 500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 33.15ms 17.65ms 209.29ms 77.50%
Req/Sec 1.56k 330.91 2.46k 66.33%
464810 requests in 30.03s, 1.06GB read
Requests/sec: 15476.11
Transfer/sec: 36.31MB
如果只是把consul作为注册中心,client与server主要是long polling,假定1分钟1个请求、1000个微服务、3w台机器、5个server
30000 * 1000 / 60 / 5 = 100,000
server如果不做扩容,可能有风险
2.2.2 Lan Gossip
很多人会担心局域网内部的Gossip带来的网络风暴。
- 笔者抓包看了一下,虽然consul节点同时监听TCP和UDP的8301端口,但实际上Gossip的数据包都是UDP包。每秒只有几个。
- Gossip包分为2类,一类是probe探针用于探活,一类是push/pull 用于交换信息
- 来看一下Gossip的默认参数
GossipLANGossipInterval 200ms // push/pull间隔
GossipLANGossipNodes 3 // push/pull选择的node数量
GossipLANProbeInterval 1s // probe间隔,其实probe node数量为1
GossipWANGossipInterval 500ms
GossipWANGossipNodes 3
所以QPS是各位数,对性能没有影响
参考笔者的文章 聊聊GOSSIP的一个实现
2.2.3 跨DC的RPC请求
这个可能是大问题,每个跨DC的RPC请求,将会导致本机房的server和目标机房的server各处理一个请求,请求压力相当于翻倍。不过还好可以通过水平扩展server来解决
似乎是更好的办法
2021年01月27日 在2.2.1中我做了定量分析,看上去单个机房中,只需要10+个consul server就能够处理所有的请求。但是单个集群的规模过大,会造成选主的速度下降,同时还增加日志同步的开销。
个人认为更稳妥的做法,还是应该借助分治法的思想,进一步划分集群
- 人为的将consul划分为多套集群,业务无相关性的服务使用不同的集群
- 逻辑上将单个机房划分成多个机房,比如
dc1-1、dc1-2... 每个机房对应1套consul集群,这样可以有效的降低单个集群的负载。另外原则上我们需要限定不允许跨机房调用。这样单个机房的实例的发布变更,仅会通知到单个机房的其它实例,而不会扩散到整个域中。 见玩转CONSUL(5)–大规模部署的性能开销定量分析(补充说明)
最后还可以给予consul实例更好的硬件配置,来提高consul server的处理能力。
后记
近期笔者才得知,consul内部对watch的数量的也有限制; 超过限制,consul节点的CPU会飙升。
在v1.2.3,限制是2048,最新的版本是8192
const (
// watchLimit is used as a soft limit to cap how many watches we allow
// for a given blocking query. If this is exceeded, then we will use a
// higher-level watch that's less fine-grained. Choosing the perfect
// value is impossible given how different deployments and workload
// are. This value was recommended by customers with many servers. We
// expect streaming to arrive soon and that should help a lot with
// blocking queries. Please see
// https://github.com/hashicorp/consul/pull/7200 and linked issues/prs
// for more context
watchLimit = 8192
)
2021年4月6日
注意
1. consul有3种一致性模型,default模式、consistent模式、stale模式。默认情况下,只有consul server(leader)真正提供对数据的查询,其它consul server(follower) 仅仅只是转发请求。
三种一致性模式中,consistent模式是强一致性的,其它两种模式都不能保证强一致性
用stale模式可以提高吞吐能力,当然数据短时间内可能会有不一致问题。详细说明见参考资料3、参考资料4。
请求形如
curl -i http://dev1:8500/v1/health/service/es?dc=dc1&passing=1&stale
- consul还支持在从consul agent上启用local cache来减少过多的查询,当然这种情况下,一致性更差。详细说明见参考资料5。
请求形如
curl -i http://dev1:8500/v1/health/service/es?dc=dc1&passing=1&cached
参看
1. Anatomy of a bug: When Consul has too much to deliver for the big day
2. Performance on large clusters Performance degrades on health blocking queries to more than 682 instances
3. Consistency Modes
4. Server Performance
5. use_cache
6. Agent Caching
2022年9月28日
如果更多的考虑可用性,而不是一致性,Netflix公司开源的Eureka可能是更好的选择。
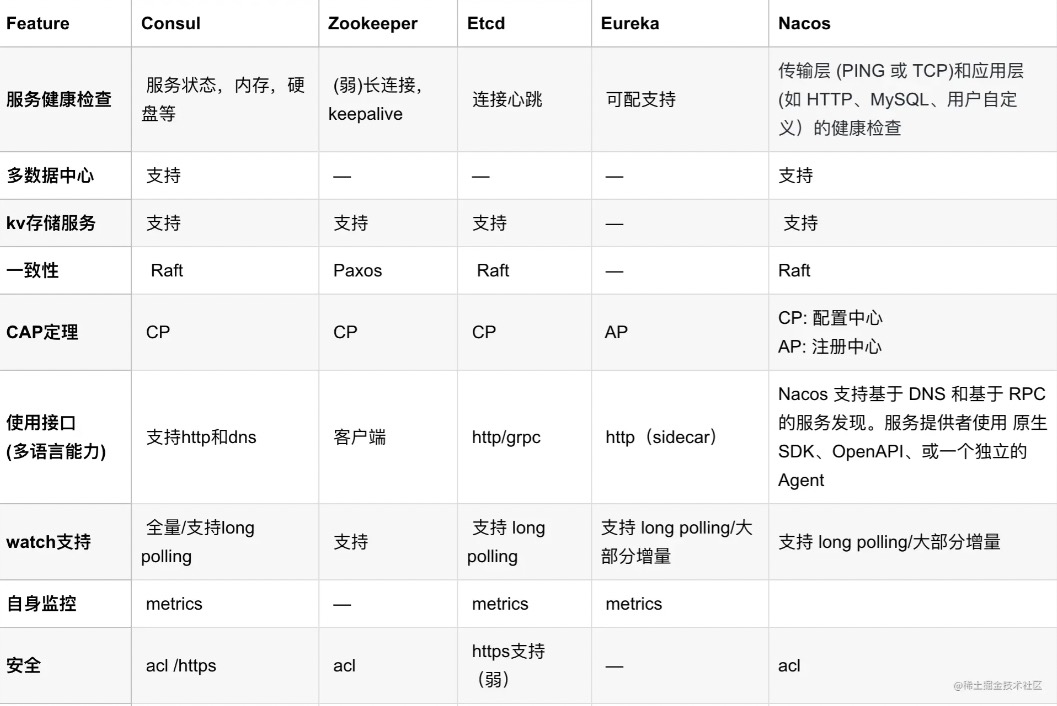
参看
1. 注册中心对比和选型:Zookeeper、Eureka、Nacos、Consul和ETCD
请我喝瓶饮料

好文章
写都是走的leader。所以其实是每个client都会连接每一个server。只是读请求是负载均衡的。而读请求你1分钟拉一次,这个频率在生产中也太低了吧。
long polling的话,其实相当于是实时的,没有啥问题
请求压力相当于翻倍。不过还好可以通过水平扩展server来解决。server不宜太大吧(日志复制、网络请求的开销)?假如扩到7台,7台抗不住怎么办?
如果单个机房内的集群规模过大,确实会带来一系列的问题。比如
1. 采用raft协议的话,会影响选主的效率
2. 日志复制的效率也会有一定的影响
内网环境中,机器通常是千M网卡,网络请求可能还好。
你的问题确实戳到了要点,我想到了某些似乎是更好的办法(见似乎是更好的答案)。核心就是
我建议就不要使用 consul了,我对于服务发现的理解 更需要关心AP,而不是CP。