AI预测模型工程化性能调优
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 前言
最近经历了一次AI预测模型工程化性能调优,这里分享出来,希望对大家有所启发。
模型是keras训练的神经网络预测模型,输入一段文本,输出文本的分类结果。为了对外提供服务,已经将模型用 gunicorn + flask对模型进行封装,提供http接口。
环境
- OS:ubuntu 18.04
- CPU:32核
- 内存: 256GB
- 显卡: Tesla P100
前期的压测结果
wrk -t4 -c100 -d30s --script=post.lua --latency http://localhost:8080/api/predict
| 类型 | CPU | GPU |
|---|---|---|
| QPS | 2.4 | 12.41 |
2. 观察性能指标
QPS过低不能满足业务方的要求,所以萌叔尝试对封装好的服务进行调优。
仔细观察了各项系统指标之后(cpu、load、磁盘IO、内存使用率、虚拟内存页换入换出)
萌叔发现了一个疑点。
2.1 keras 使用CPU
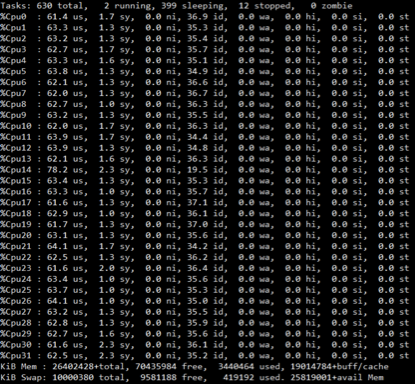
在压测的过程中,CPU的使用率只能达到70%左右
2.2 keras 使用GPU
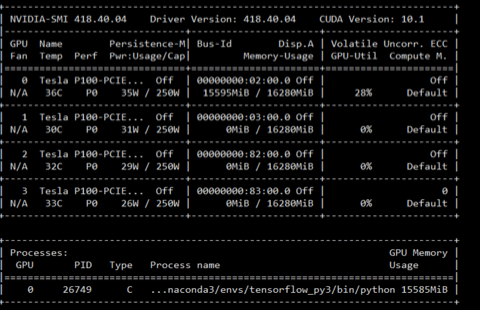
在压测的过程中,GPU的使用率只能达到30%左右
神经网络模型对文本分类的预测过程,实际就是将输入文本转换成数值,再带入神经网络,进行的2次计算的过程。这是一个计算密集型的场景,性能瓶颈应该是CPU/GPU; 如果CPU、GPU没有打满,则说明性能仍有提升的空间。
3. 调优
3.1 初始协程模式
web使用Flask开发,启动脚本如下:
gunicorn -k gevent -t 300 -b 0.0.0.0:8080 run:app
gunicorn有几种工作模式
- sync (进程模式)
- eventlet
- gevent (协程模式)
- tornado
- gthread
gevent是一种协程模式,它的特点是在请求的处理过程中有IO调用时(或者当前的协程主动让出CPU),会自动触发切换上下文切换,启动另一个协程,提高CPU的利用率。它特别适用于IO密集型的场景,尤其是对于处理过程中有对数据库的调用,第三方服务调用的情况。
然而本文的场景是模型运算过程,是计算密集型的场景,使用gevent可能并不合适。
3.2 尝试使用进程模式
gunicorn -w 5 -k sync -t 300 -b 0.0.0.0:8080 run:app
3.2.1 keras 使用CPU

在压测的过程中,CPU使用率95%
3.2.2 keras 使用GPU
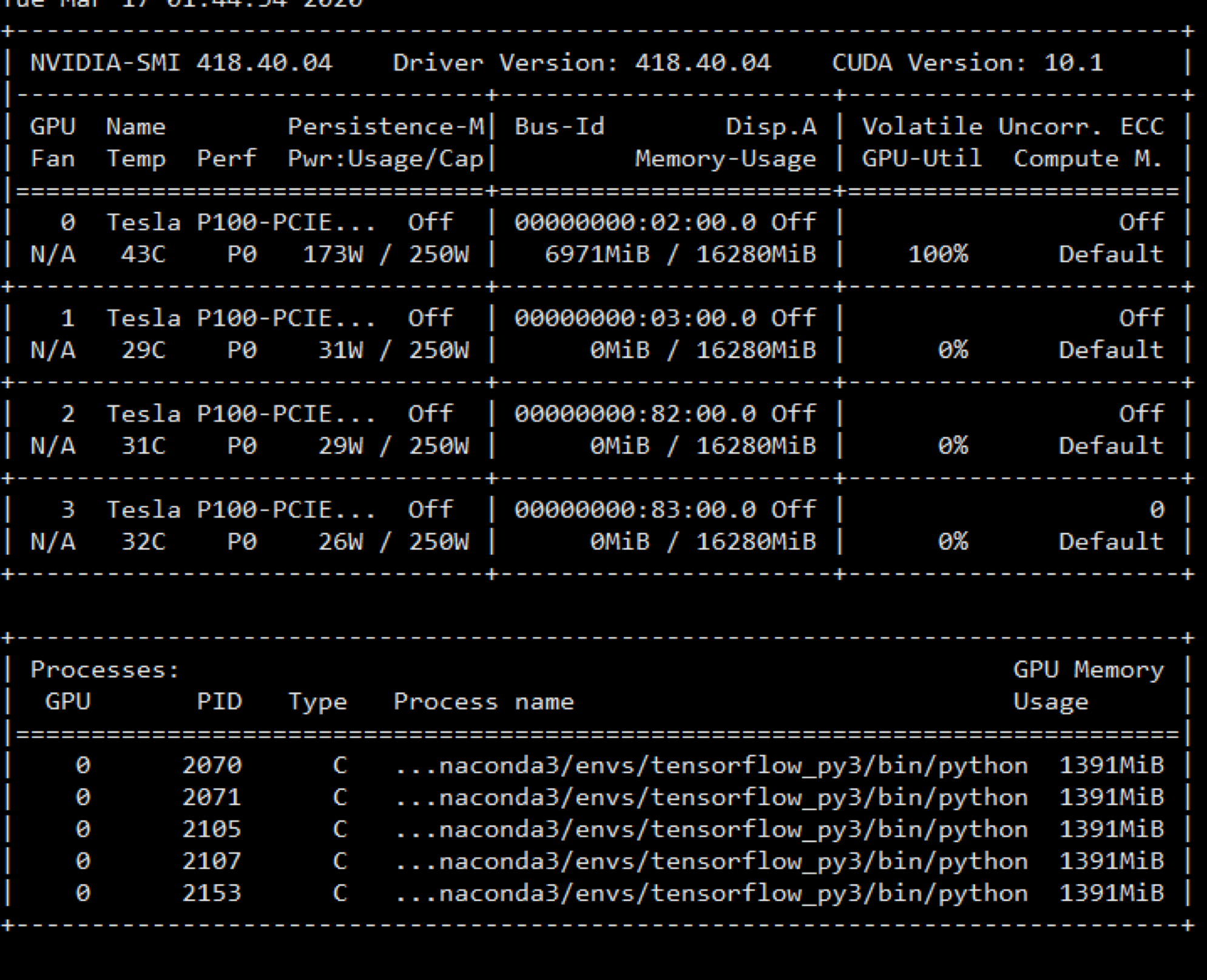
在压测的过程中,GPU使用率100%
可见性能已经达到了极限,优化结束。
TIP
使用gunicorn配置成进程模式后,启动时报"GPU out of memory"
此时可设置GPU显存动态装载,解决这个问题,详见参考资料2
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # dynamically grow the memory used on the GPU
config.log_device_placement = True # to log device placement (on which device the operation ran)
# (nothing gets printed in Jupyter, only if you run it standalone)
sess = tf.Session(config=config)
set_session(sess) # set this TensorFlow session as the default session for Keras
4. 总结
最后让我们来对比一下,优化前和优化后的结果
| 类型 | CPU | GPU |
|---|---|---|
| 优化前-QPS | 2.4 | 12.41 |
| 优化后-QPS | 3.36 | 42.19 |
可以看出QPS提升明显,尤其是使用GPU的情况。
提问?
正常情况gunicorn使用gevent,只能打满一个CPU核,为什么在当keras使用CPU时,多个CPU核的使用率都达到了70%左右。
萌叔的回答
当协程处理请求时,执行模型预测函数
model.predict()
predict函数原型
predict(x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
由协程创建了多进程,而这些进程其实都是不在gevent的控制范围内的
参考资料
1.keras
2.Using allow_growth on keras with tensorflow
3.gunicorn-worker_class
后记
2021年5月19日
回答读者提问
Q:看到您在该篇博客中(https://vearne.cc/archives/39300)写到模型预测时,cpu利用率一直不高是io导致的上下文切换。
不知大佬对于java运行模型预测的类似问题,有无解决方案呢?A:其实不完全是IO上下文切换的问题,是没有充分利用CPU、GPU
正常情况的协程,对应的都是操作系统的单线程,只能打满一个CPU核,
如果物理机的CPU是16核,你只能跑满1个核,那其余15核是不是就浪费了,仅此而已。解决方法:
类似的场景比如redis服务,早期redis实例都是单线程的,为了充分利用服务器资源,都是一个物理机上部署多个实例。
java的服务如果是多线程的,是能够打满多核的,不必要担心这个问题
这里强调一下,像netty这样单线程模型的web服务也是会有问题,可以尝试一下像tomcat这样的多线程web服务。

模型预测的时候,并不推荐进行上下文切换?
基于神经网络的模型预测,是CPU密集型的场景,频繁的上下文切换毫无益处可言