玩转CONSUL(6)–consul读写分离方案
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
1. 引言
在萌叔之前的文章里,我曾经提到过使用consul进行注册和发现的时候,consul agent默认情况下,只会转发watch请求,所以负载最终还是会施加在consul server上。
为了解决这个问题,有如下几种方案:
1.1 降低watch的频率
1.1.1 增加wait参数的值
1.1.2 打开consul agent的cache功能
不过使用consul agent的cache可能导致在一个很短的时间窗口数据不一致
1.1.3 在watch请求返回之后,增加sleep
同1.1.2 在很短的时间窗口,数据可能不一致
1.2 增强Consul Server的处理能力
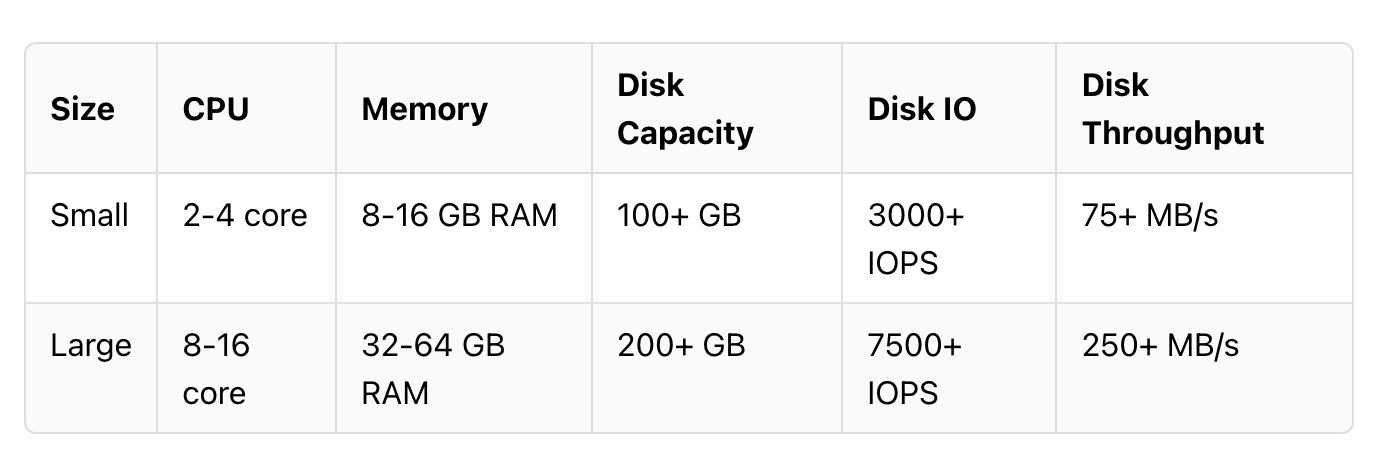
官方推荐Consul Server硬件配置,可以达到8~16核,内存可以达到32~64GB
1.3 增加Consul Server的数量
官方推荐的Consul Server的数量一般不超过5个。增加Consul Server的数量,确实可以提高整个集群的读请求的负载能力,但是由于Server数量增多,达成共识的速度可能会下降,也就是说,可能会影响写能力。
1.4 Enterprise feature: enhanced read scalability
Read-heavy clusters (e.g. high RPC call rate, heavy DNS usage, etc.) will generally be bound by CPU and may take advantage of the read replicas Enterprise feature for improved scalability. This feature allows additional Consul servers to be introduced as non-voters. As a non-voter, the server will still participate in data replication, but it will not block the leader from committing log entries. Additional information can be found in the Server Performance section of the Consul product documentation.
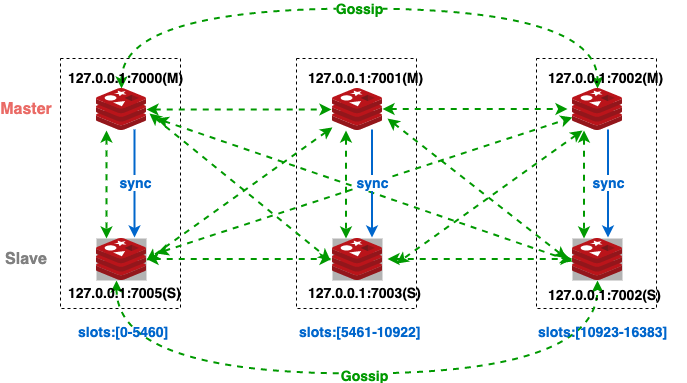
官方在文档中还提到了另一种方法。类似于Redis Cluster模式中的Slave节点,Consul的企业版引入了只读节点,这些只读节点不参与Raft协议的数据的写操作,只是简单复制Consul Server的数据,分担读压力。在Master节点宕机的情况下,其可以通过发起投票的方式,将自己转变为Master。
2. 读写分离方式
如果我们把Consul Server的数据写入过程类比为人类社会议会的决议讨论,那么为了尽快达成决议,肯定是参加讨论的议员越少越好。决议一旦形成,只要把这个结果发布出去就行。然而Consul集群的做法,相当于不断地有人去问议员。这种做法显然会影响决议的形成。(读操作也会干扰写操作的执行速度)
考虑到读写分离的思想
萌叔开发了项目 vearne/consul-cache
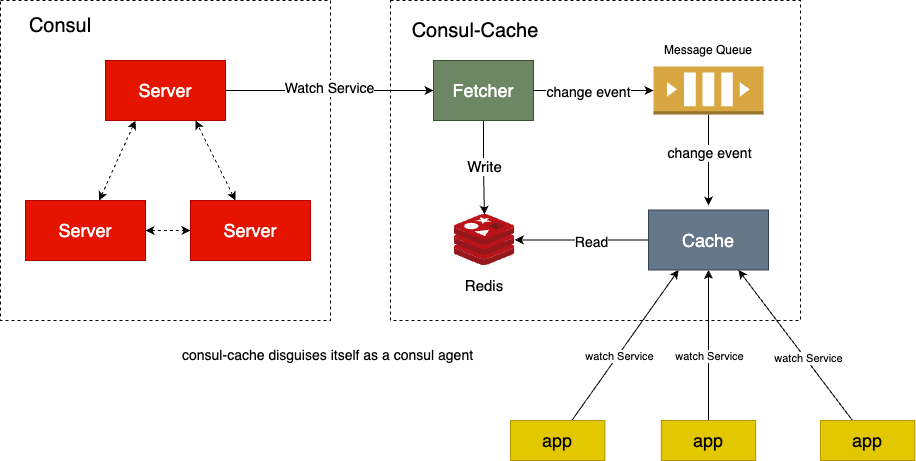
consul-cache包含2个组件
Fetcher从consul发现服务变化并在Redis中构建该服务对应的所有实例-
Cache将自己伪装成consul agent,以便业务程序执行watch操作
由于consul-cache某种意义上说,只是一个带消息队列的local cache,因此它可以很方便的进行水平扩展。另外由于有消息队列的存在,Cache 中的数据和consul server中的数据,也可以保证最终一致性。
整套方案,萌叔已经完成了初步的验证,欢迎大家提issue和PR。
参考资料
1.Consul reference architecture
