lucene中的 *.del文件
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
注意:本文基于lucene 3.1
引言
最近一直在看lucene相关的资料,今天介绍一下lucene中的索引文件的一部分
*.del文件
概述
如果索引文件中,有被删除的doc,则lucene会创建*.del文件
*.del 记录了被删除doc的ID
采用2中方法
1)BitVector
BitVector等同于C++中的bitset,每个bit对应一个doc
如下图,假定共有24个doc,其中10、12被删除
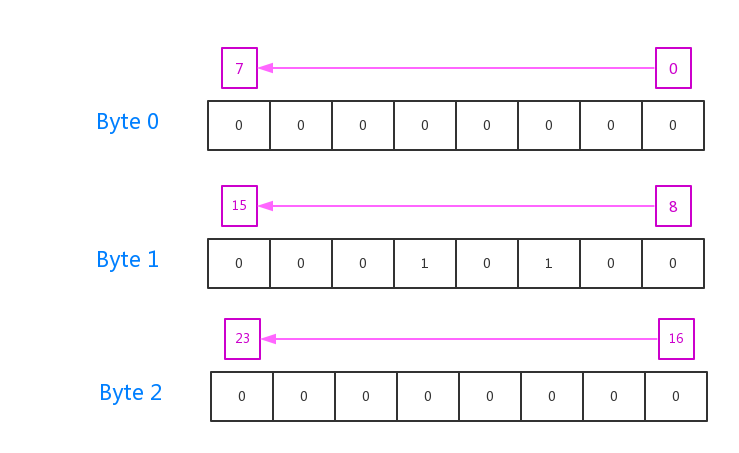
注意 在一个segment中,doc ID从0开始
2) DGaps
如果segment中的文档数量较多,而被删除的文档很少,那么将有大量的bit为0,少量为1。这种稀疏的BitVector,非常浪费存储空间。因此lucene提供了
DGaps这种存储格式,我们可以把它看做是BitVector的一种压缩格式。

它的思想是这样的,只有少量的bit被置为1,那么就只记录非0的字节,
所以对于每个非0的字节,需要一个二元组去记录
(Dgap, NonzeroByte)
Dgap 表示该字节是第几个字节(从0开始,用vint表示, 关于vint可参考我的另一篇文章VINT–针对INT型的压缩格式)
NonzeroByte 表示这个字节的值
对于上面的例子,只有byte1 是非0字节,所以最终结果如下
00000001 00010100
参考资料
1.Apache Lucene - Index File Formats
请我喝瓶饮料
