Lucene索引结构漫谈
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
前言
注意: 本文基于Lucene 3.0.2, 目前Lucene的版本最新已经是7.3.x
虽然Lucene的版本变化较大, 但是索引结构已经构建它的核心思想并没有发生。
Lucene是solr和Elasticsearch的基础,汽车中的引擎,它的每次改版都会引起上层系统的巨大变化。研究它对于提升查询性能,降低存储开销有非常大的帮助。
笔者有三年多的ES使用经验,但是真正踏踏实实探究Lucene和ES也是最近时间的事情。
重要
首先,推荐的是一本书《Lucene实战》这本书的作者有好几个都是Lucene的核心开发人员,因此对Lucene的理解是非常透彻的, 非常推荐。
推荐索引文件的查看工具Luke, 它可以打开Lucene和ES的索引文件,直观的观察它们的内部数据
1. 索引文件列表
Lucene有2种文件格式
1.1 CompoundFile == false
-rw-r--r-- 1 zhuwei wheel 1471 6 5 15:44 _2.fdt
-rw-r--r-- 1 zhuwei wheel 12 6 5 15:44 _2.fdx
-rw-r--r-- 1 zhuwei wheel 66 6 5 15:44 _2.fnm
-rw-r--r-- 1 zhuwei wheel 323 6 5 15:44 _2.frq
-rw-r--r-- 1 zhuwei wheel 8 6 5 15:44 _2.nrm
-rw-r--r-- 1 zhuwei wheel 442 6 5 15:44 _2.prx
-rw-r--r-- 1 zhuwei wheel 61 6 5 15:44 _2.tii
-rw-r--r-- 1 zhuwei wheel 2611 6 5 15:44 _2.tis
-rw-r--r-- 1 zhuwei wheel 9 6 5 15:44 _2.tvd
-rw-r--r-- 1 zhuwei wheel 1647 6 5 15:44 _2.tvf
-rw-r--r-- 1 zhuwei wheel 20 6 5 15:44 _2.tvx
-rw-r--r-- 1 zhuwei wheel 20 6 5 15:44 segments.gen
-rw-r--r-- 1 zhuwei wheel 233 6 5 15:44 segments_4
1.2 CompoundFile == true
total 33976
-rw-r--r-- 1 zhuwei wheel 2459065 7 31 13:17 _0.cfs
-rw-r--r-- 1 zhuwei wheel 13468962 7 31 13:17 _0.cfx
-rw-r--r-- 1 zhuwei wheel 1451842 7 31 13:17 _1.cfs
-rw-r--r-- 1 zhuwei wheel 20 7 31 13:17 segments.gen
-rw-r--r-- 1 zhuwei wheel 442 7 31 13:17 segments_2
组合文件只是将原来放在多个文件中的数据整合到少数的几个文件中,减少了打开的文件描述符的数量,其它并没有大的区别,所以我们重点来看非组合文件。
2. Summary of File Extensions(不同扩展名的文件说明)
这里并不列出所有的
| Name | Extension | Brief Description |
|---|---|---|
| Segments File | segments.gen, segments_N | Stores information about segments(存储段信息) |
| Lock File | write.lock | The Write lock prevents multiple IndexWriters from writing to the same file.一个index某一时刻只允许一个IndexWriter进行操作(与IndexWriter对应的是IndexReader, 它们对文件的访问有点像在操作读写锁) |
| Fields | .fnm | Stores information about the fields, 存储字段元信息,字段类型/名称等等 |
| Field Index | .fdx | Contains pointers to field data.注解2.1 |
| Field Data | .fdt | The stored fields for documents.注解2.1 |
| Term Infos | .tis | Part of the term dictionary, stores term info注解2.2 |
| Term Info Index | .tii | The index into the Term Infos file注解2.2 |
| Frequencies | .frq | Contains the list of docs which contain each term along with frequency |
| Positions | .prx | Stores position information about where a term occurs in the index |
| Norms | .nrm | Encodes length and boost factors for docs and fields |
| Term Vector Index | .tvx | Stores offset into the document data file |
| Term Vector Documents | .tvd | Contains information about each document that has term vectors |
| Term Vector Fields | .tvf | The field level info about term vectors |
| Deleted Documents | .del | Info about what files are deleted, Lucene中删除和更新操作本质都是追加操作, 如果此Segment没有文件被删除,则该Segment 中对应的.del文件不存在 |
注解2.1 .fdx 和 .fdt
所以他们存储在不同的文件中,一个doc中所有Field数据都是存储在.fdt文件中, 它需要和.fdx文件配合使用, 它们的关系如下图:
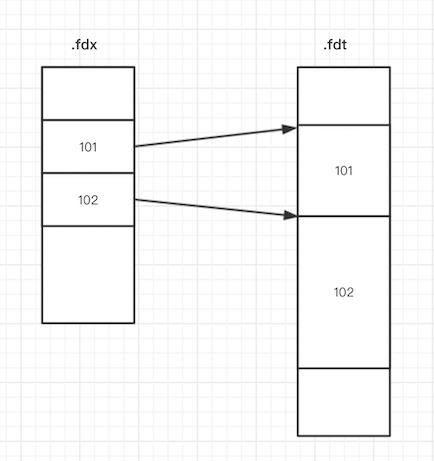
可以通过设置 Field.Store.NO, 不存储这个Field的原始数据
注意:原始数据和索引 是2种不同的东西, 1个doc能够被检索出来,但是这个doc中的Field信息可以完全不存储
Query and Fetch
在一次正常检索过程中,可以理解为以下2个阶段
- 1)query --> DocID 102、DocID 245
- 2) 拿着DocID102、245到.fdx和.fdt中获取实际的doc内容
这里做一个简单的说明,
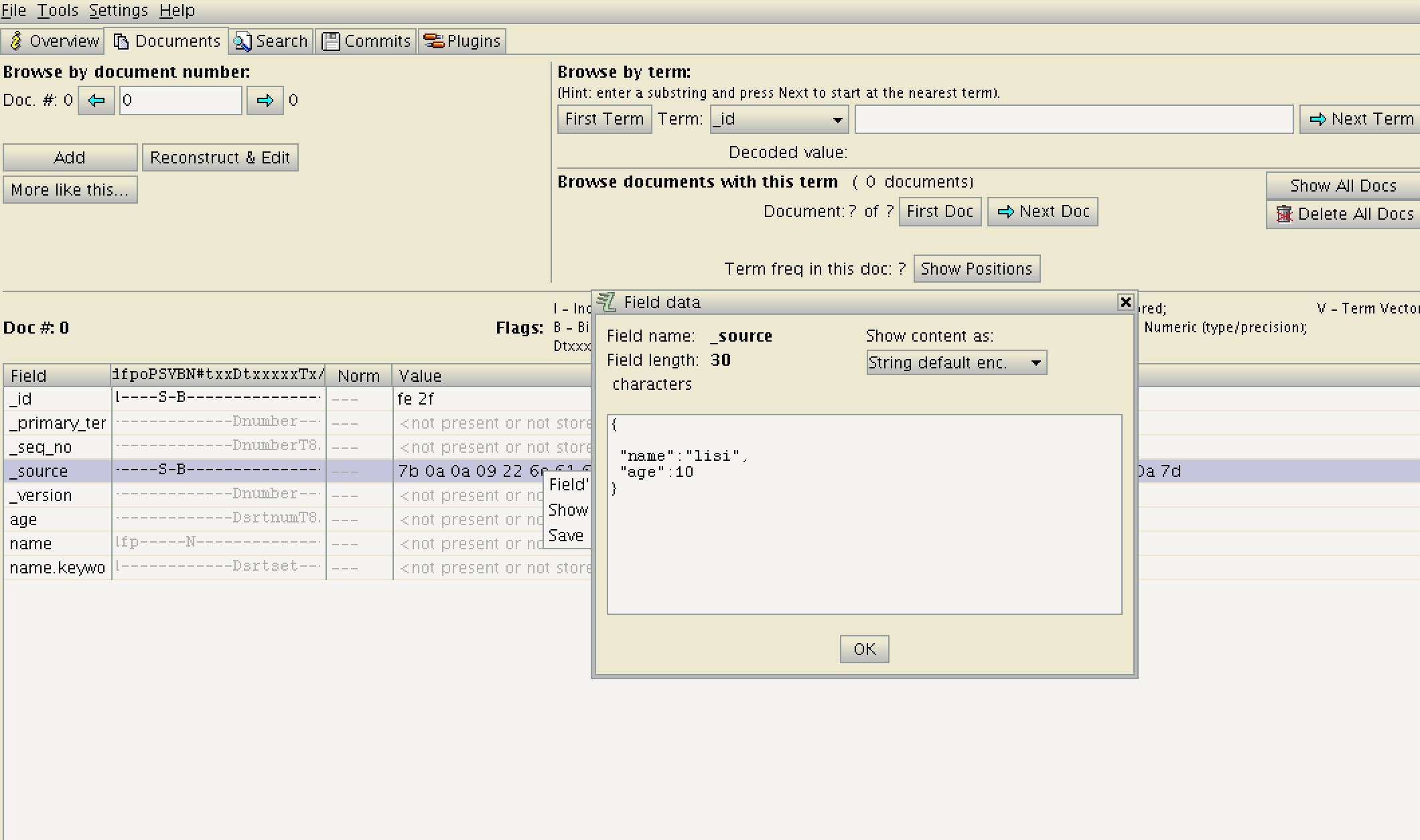
上图是用luke打开的ES v6.2.4的一个索引段
ES中的情况比较特别,ES额外增加了一个字段_source 存储了整个doc, 对应上图的内容。
{
"name": "lisi",
"age": 10
}
这样获取doc内容只需要读取一次_source 字段,而不需要对每个字段都读取一次。
注解2.2 .tis和.tii
文章到了这里才是重头戏, .tii是.tis对应的索引文件, .tii是由.tis文件抽取的方式生成的,由IndexInterval来控制。 .tii中IndexDelta是对应的TermInfo在.tii中的文件偏移量。
下图中IndexInterval=4, 粗略的估算.tii文件会是.tis文件大小的1/4, 在Lucene 3.0.2中,此值为128。
注意1 网上有资料说,在Elasticsearch中.tii会被整个装载在内存中,无法进行优化,所以控制.tii的文件大小就显得至关重要,但萌叔认为这个说法存疑。
注意2 由于Term本身的长度是不确定的,另外DocFreq等整数都采用Vint格式进行存储,所以TermInfo的长度是不确定的,不是固定长度。
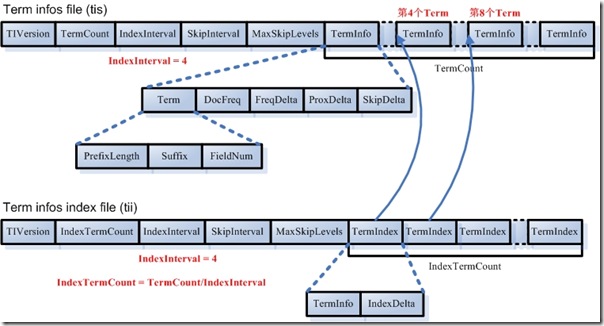
下面让我们来看看.tis文件的大体内容
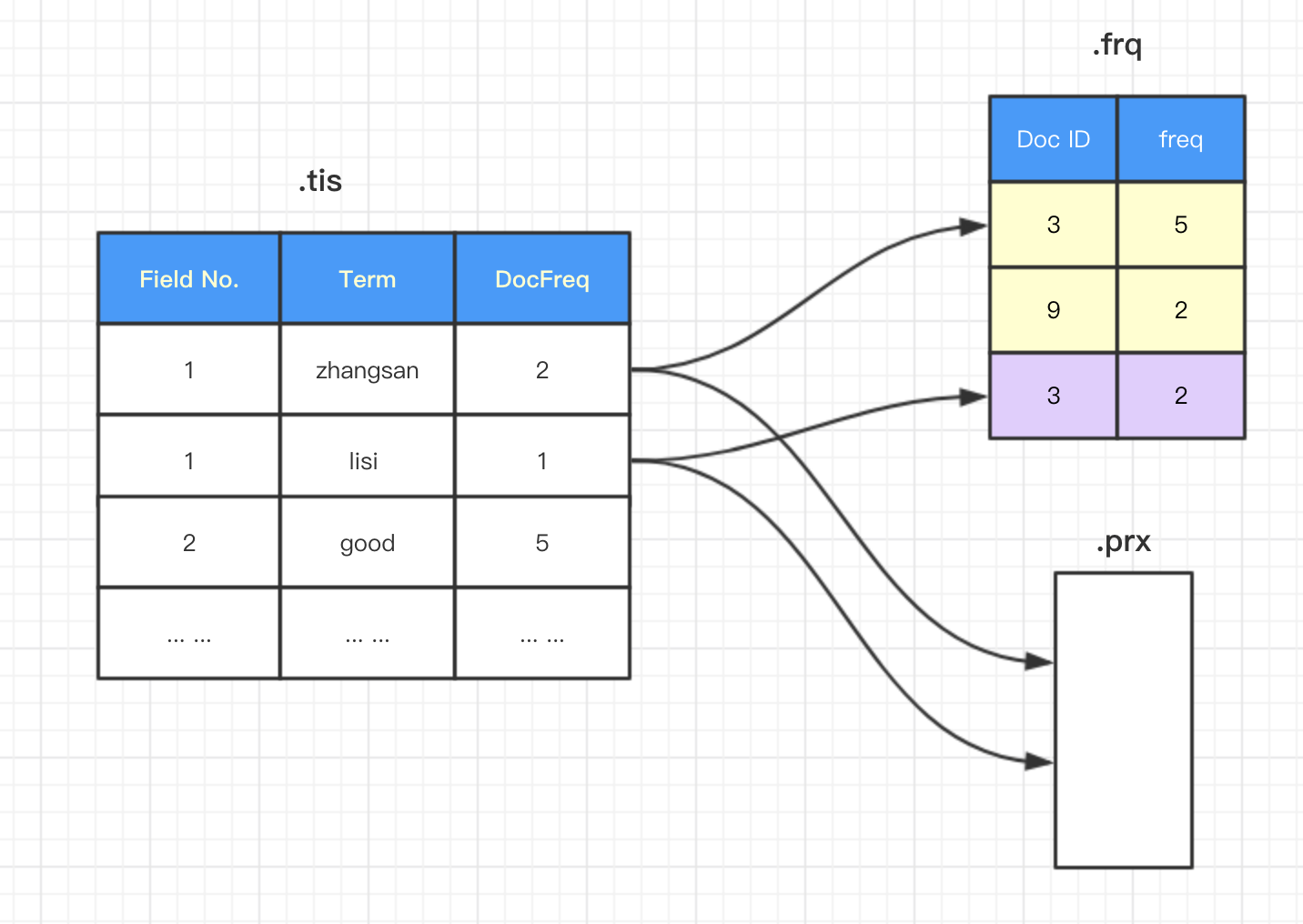
在.tis文件中(Field Number, Term) 构成的二元组按照字典序排列,对于上图,Field 1 中"zhangsan"这个Term在该Segment中,共出现在2个doc中,分别是doc3和9,其中在doc3中"zhangsan"这个Term出现了5次,其中在doc9中"zhangsan"这个Term出现了2次; Field 1 中"lisi"这个Term在该Segment中,共出现在1个doc中,在doc3中"lisi"这个Term出现了2次。
注意:这里的SkipInterval和MaxSkipLevels是.frq文件中跳跃表的相关参数,这个跳跃表存在意义是快速查找特定Term在某个doc中position
详细见参考资料4
.prx文件中存储是Term出现的位置信息
3. 索引的目的是为了服务于查询
构建索引的最终目的,还是为了能够快速的检索,让我们来看看,一个常见Lucene Query是什么样的。
grade:{60,80] AND name:zhangsan
翻译过来大体就是这样
(grade > 60 && grade <= 80) && name == "zhangsan"
获取name为"zhangsan"且,grade大于60且小于等于80的doc
Lucene需要支持
- TermQuery Term查询
- PhraseQuery 短语查询
- WildcardQuery 通配符查询
- PrefixQuery 前缀查询
- FuzzyQuery 同义词查询
- NumericRangeQuery 数值型数据的范围查询
- TermRangeQuery String型数据的范围查询
还需要支持布尔操作符
- AND
- OR
- NOT
在2.2 中我们讲到(Field Number, Term) 构成的二元组按照字典序排列,因此Lucene能够很容易的支持TermQuery/PrefixQuery/TermRangeQuery
4. 数值型数据的检索
- 在Lucene中没有针对Date的Query,Date类型只能够转换成数值型数据,然后存入索引
- 数值型的数据都需要转换成
Term
转换出的Term所占空间
| Type | Term size |
|---|---|
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
转换方法是增函数,转换后保持数值的大小关系不变,因此可以很容易的支持NumericRangeQuery。
5. doc的更新和删除
在Lucene的体系中, 一个 Index中可以有多个Segment, 每个Segment中, doc ID都是从0开始编号,并且唯一
- Lucene中其实是没有对doc的真正意义上的更新的。Lucene中采取的是先删除,再追加的方式
- 删除也是一种追加动作,被删除的
docID 会记录在.del文件中, 关于.del文件的结构可以参看LUCENE中的 *.DEL文件 - 只有在多个
Segment执行optimize(主要是merge Segment)的时候, 被删除的doc才会实际被移除,空间才能够释放
6. 其它
其实在Lucene 中有很多的索引相关数据,是没有必要被存储的。Lucene提供了相关配置可以进行自定义的配置
Field.Index
- Field.Index.ANALYZED
- Field.Index.NOT_ANALYZED
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
TermVector
- TermVector.YES
- TermVector.NO
- TermVector.WITH_POSITIONS
- TermVector.WITH_OFFSETS
- TermVector.WITH_POSITIONS_OFFSETS
PS: Lucene比较复杂,笔者水平有限,如有错误,不吝赐教。
参考资料
请我喝瓶饮料
