关联规则算法-Eclat
版权声明 本站原创文章 由 萌叔 发表
转载请注明 萌叔 | https://vearne.cc
前言
最近打算给我的博客做个性化推荐,初步选定使用关联规则算法来实现。
常见关联规则算法又有Apriori算法、FP-树频集算法、Eclat算法 3种。
请务必阅读参考资料1,了解Support(支持度), Confidence(置信度), Lift(提升度)
Association rules are usually required to satisfy a user-specified minimum support and a user-specified minimum confidence at the same time. Association rule generation is usually split up into two separate steps:
A minimum support threshold is applied to find all frequent itemsets in a database.
A minimum confidence constraint is applied to these frequent itemsets in order to form rules.
While the second step is straightforward, the first step needs more attention.
关联规则一般分为2步
1) 根据最小支持度查找所有的频繁的项目集(itemsets)
2) 根据最小置信度,在1)找出的频繁的项目集中, 创建关联规则
第2步比较简单,重点关注第1步,寻找频繁的项目集
Eclat算法
Eclat算法是一种基于集合交集的深度优先搜索算法。 它适用于具有局部性增强特性的顺序执行和并行执行。笔者先实现了Python版,后期可以直接实现Spark版本,进行并行化计算。
首先看下参考资料2举的例子
表1:关联规则的简单例子
| TID | 网球拍 | 网球 | 运动鞋 | 羽毛球 |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 0 |
| 2 | 1 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 |
| 4 | 1 | 0 | 1 | 0 |
| 5 | 0 | 1 | 1 | 1 |
| 6 | 1 | 1 | 0 | 0 |

为了计算方便,我们把网球拍等商品直接用A ~ D来取代
表2
| TID | items |
|---|---|
| 1 | A,B,C |
| 2 | A,B |
| 3 | A |
| 4 | A,C |
| 5 | B,C,D |
| 6 | A,B |
Eclat算法加入了倒排的思想,以商品项为key,以事务为value
表3
| item | Tids |
|---|---|
| A | 1,2,3,4,6 |
| B | 1,2,5,6 |
| C | 1,4,5 |
| D | 5 |
在这里把
- 以1个商品项构建项集,称为1项集
- 以2个商品项构建项集,称为2项集
- 以3个商品项构建项集,称为3项集
以此类推
可知表3 就是1项集,如果它们满足指定支持度,就是频繁1项集
基本思想
要得到频繁项集,如果不考虑性能,我们需要穷举商品[A-D]的能构成的所有组合,然后判断该项集是否是频繁项集。解空间可以构成如下的树
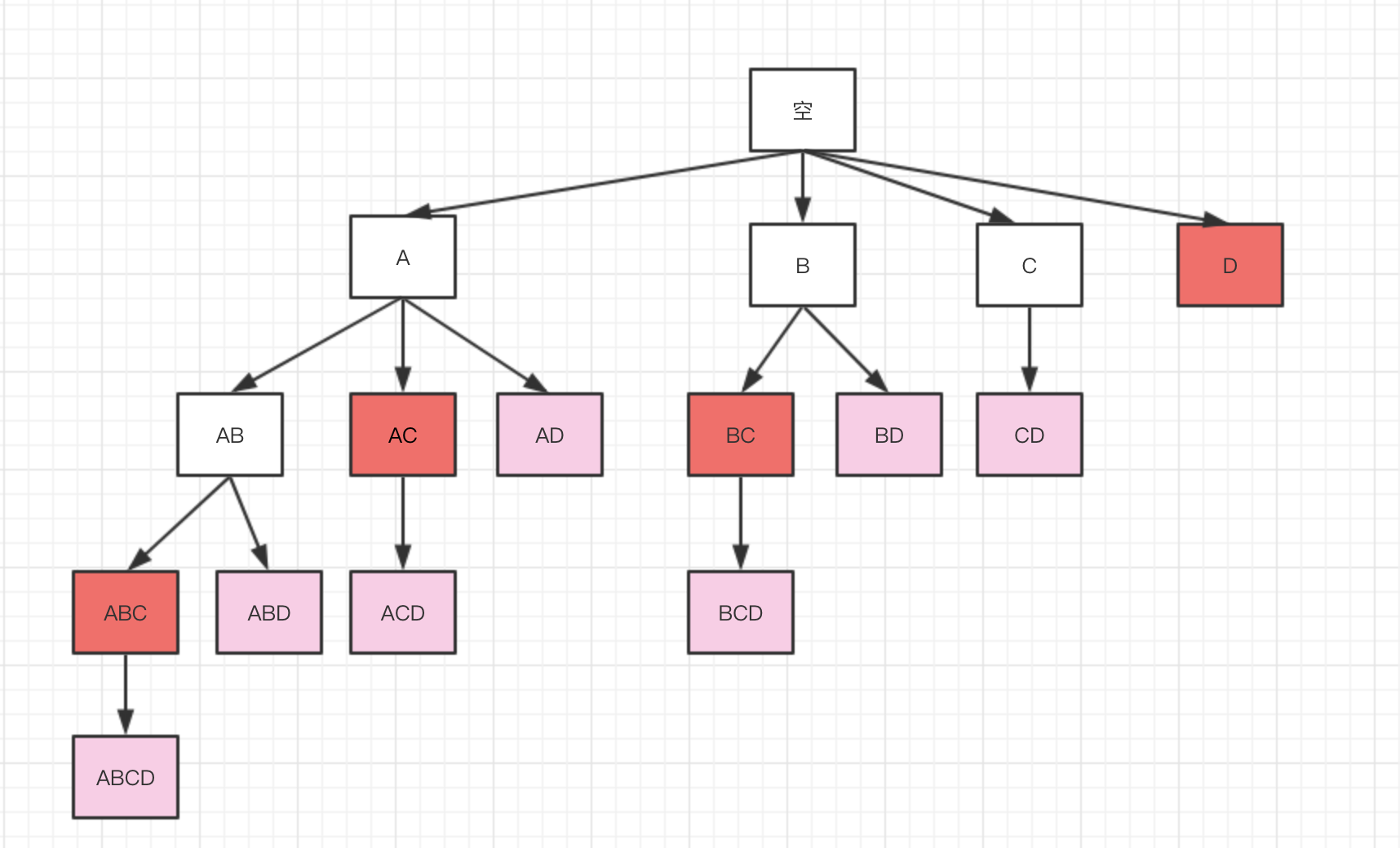
我们知道,如果k + 1项集是频繁项集,那么k项集一定是频繁项集,反之如果k项集不是频繁项集,那么果k + 1项集一定不是频繁项集。根据此规则,我们能对解空间的搜索进行裁剪。上图中的粉红色节点表示当支持度是0.5时,能够被裁剪掉的节点。
Eclat算法思想是 由频繁k项集求交集,生成候选k+1项集 。对候选k+1项集做裁剪,生成频繁k+1项集,再求交集生成候选k+2项集。如此迭代, 直到搜索完整个解空间。
详细代码见
eclat.py
参考资料
请我喝瓶饮料
